

Authors:
(1) Omri Avrahami, Google Research and The Hebrew University of Jerusalem;
(2) Amir Hertz, Google Research;
(3) Yael Vinker, Google Research and Tel Aviv University;
(4) Moab Arar, Google Research and Tel Aviv University;
(5) Shlomi Fruchter, Google Research;
(6) Ohad Fried, Reichman University;
(7) Daniel Cohen-Or, Google Research and Tel Aviv University;
(8) Dani Lischinski, Google Research and The Hebrew University of Jerusalem.
Table of Links
- Abstract and Introduction
- Related Work
- Method
- Experiments
- Limitations and Conclusions
- A. Additional Experiments
- B. Implementation Details
- C. Societal Impact
- References
3. Method
As stated earlier, our goal in this work is to enable generation of consistent images of a character (or another kind of visual subject) based on a textual description. We achieve this by iteratively customizing a pre-trained text-to-image model, using sets of images generated by the model itself as training data. Intuitively, we refine the representation of the target character by repeatedly funneling the model’s output into a consistent identity. Once the process has converged, the resulting model can be used to generate consistent images of the target character in novel contexts. In this section, we describe our method in detail.
Formally, we are given a text-to-image model MΘ, parameterized by Θ, and a text prompt p that describes a target character. The parameters Θ consist of a set of model weights θ and a set of custom text embeddings τ . We seek a representation Θ(p), s.t., the parameterized model MΘ(p) is able to generate consistent images of the character described by p in novel contexts.
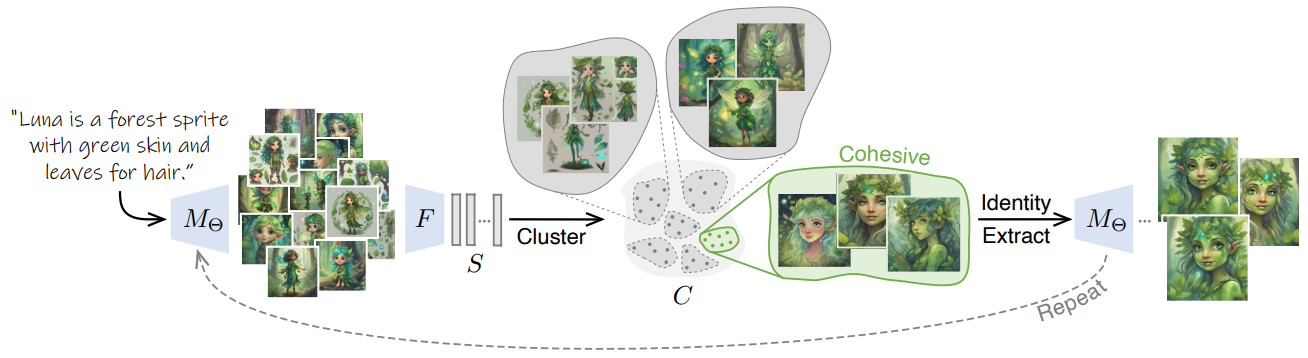
Our approach, described in Algorithm 1 and depicted in Figure 3, is based on the premise that a sufficiently large set of images generated by M for the same text prompt, but with different seeds, will reflect the non-uniform density of the manifold of generated images. Specifically, we expect to find some groups of images with shared characteristics. The “common ground” among the images in one of these groups can be used to refine the representation Θ(p) so as to better capture and fit the target. We therefore propose to iteratively cluster the generated images, and use the most cohesive cluster to refine Θ(p). This process is repeated, with the refined representation Θ(p), until convergence. Below, we describe the clustering and the representation refinement components of our method in detail.
3.1. Identity Clustering

![Figure 4. Embedding visualization. Given generated images for the text prompt “a sticker of a ginger cat”, we project the set S of their high-dimensional embeddings into 2D using t-SNE [29] and indicate different K-MEANS++ [4] clusters using different colors. Representative images are shown for three of the clusters. It may be seen that images in each cluster share the same characteristics: black cluster — full body cats, red cluster — cat heads, brown cluster — images with multiple cats. According to our cohesion measure (1), the black cluster is the most cohesive, and therefore, chosen for identity extraction (or refinement).](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-wca3zpw.png)
In Figure 4 we show a visualization of the DINOv2 embedding space, where the high-dimensional embeddings S are projected into 2D using t-SNE [29] and colored according to their K-MEANS++ [4] clusters. Some of the embeddings are clustered together more tightly than others, and the black cluster is chosen as the most cohesive one.
3.2. Identity Extraction

We base our solution on a pre-trained Stable Diffusion XL (SDXL) [57] model, which utilizes two text encoders: CLIP [61] and OpenCLIP [34]. We perform textual inversion [20] to add a new pair of textual tokens τ , one for each of the two text encoders. However, we found that this parameter space is not expressive enough, as demonstrated in Section 4.3, hence we also update the model weights θ via a low-rank adaptation (LoRA) [33, 71] of the self- and cross-attention layers of the model.
We use the standard denoising loss:

3.3. Convergence
As explained earlier (Algorithm 1 and Figure 3), the above process is performed iteratively. Note that the representation Θ extracted in each iteration is the one used to generate the set of N images for the next iteration. The generated images are thus funneled into a consistent identity.

Finally, it should be noticed that our method is nondeterministic, i.e., when running our method multiple times, on the same input prompt p, different consistent characters will be generated. This is aligned with the one-to-many nature of our task. For more details and examples, please refer to the supplementary material.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.