

Authors:
(1) Omri Avrahami, Google Research and The Hebrew University of Jerusalem;
(2) Amir Hertz, Google Research;
(3) Yael Vinker, Google Research and Tel Aviv University;
(4) Moab Arar, Google Research and Tel Aviv University;
(5) Shlomi Fruchter, Google Research;
(6) Ohad Fried, Reichman University;
(7) Daniel Cohen-Or, Google Research and Tel Aviv University;
(8) Dani Lischinski, Google Research and The Hebrew University of Jerusalem.
Table of Links
- Abstract and Introduction
- Related Work
- Method
- Experiments
- Limitations and Conclusions
- A. Additional Experiments
- B. Implementation Details
- C. Societal Impact
- References
B. Implementation Details
In this section, we provide the implementation details that were omitted from the main paper. In Appendix B.1 we provide the implementation details of our method and the baselines. Then, in Appendix B.2 we provide the implementation details of the automatic metrics that we used to evaluate our method against the baselines. In Appendix B.3 we provide the implementation details and the statistical analysis for the user study we conducted. Lastly, in Appendix B.4 we provide the implementation details for the applications we presented.
B.1. Method Implementation Details
We based our method, and all the baselines (except ELITE [90] and BLIP-diffusion [42]) on Stable Diffusion XL (SDXL) [57], which is the state-of-the-art open source text-to-image model, at the writing of this paper. We used the official ELITE implementation, that uses Stable Diffusion V1.4, and the official implementation of BLIPdiffusion, that uses Stable Diffusion V1.5. We could not replace these two baselines to SDXL backbone, as the encoders were trained on these specific models. As for the rest of the baselines, we used the same SDXL architecture and weights.

List of the third-party packages that we used:
• Official SDXL [57] implementation by HuggingFace Diffusers [86] at https : / / github . com / huggingface/diffusers
• Official SDXL LoRA DB implementation by HuggingFace Diffusers [86] at https : / / github . com / huggingface/diffusers. • Official ELITE [90] implementation at https : / / github.com/csyxwei/ELITE
• Official BLIP-diffusion [42] implementation at https: / / github . com / salesforce / LAVIS / tree / main/projects/blip-diffusion
• Official IP-adapter [93] implementation at https:// github.com/tencent-ailab/IP-Adapter
• DINOv2 [54] ViT-g/14, DINOv1 [14] ViT-B/16 and CLIP [61] ViT-L/14 implementation by HuggingFace Transformers [91] at https : / / github . com / huggingface/transformers
B.2. Automatic Metrics Implementation Details
In order to automatically evaluate our method and the baselines quantitatively, we instructed ChatGPT [53] to generate prompts for characters of different types (e.g., animals, creatures, objects, etc.) in different styles (e.g., stickers, animations, photorealistic images, etc.). These prompts were then used to generate a set of consistent characters by our method and by each of the baselines. Next, these prompts were used to generate these characters in a predefined collection of novel contexts from the following list:
• “a photo of [v] at the beach”
• “a photo of [v] in the jungle”
• “a photo of [v] in the snow”
• “a photo of [v] in the street”
• “a photo of [v] with a city in the background”
• “a photo of [v] with a mountain in the background”
• “a photo of [v] with the Eiffel Tower in the background”
• “a photo of [v] near the Statue of Liberty”
• “a photo of [v] near the Sydney Opera House”
• “a photo of [v] floating on top of water”
• “a photo of [v] eating a burger”
![Table 2. Statistical analysis. We use Tukey’s honestly significant difference procedure [83] to test whether the differences between mean scores in our user study are statistically significant.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-2aa3zeb.png)
• “a photo of [v] drinking a beer”
• “a photo of [v] wearing a blue hat”
• “a photo of [v] wearing sunglasses”
• “a photo of [v] playing with a ball”
• “a photo of [v] as a police officer”
where [v] is the newly-added token that represents the consistent character.
B.3. User Study Details
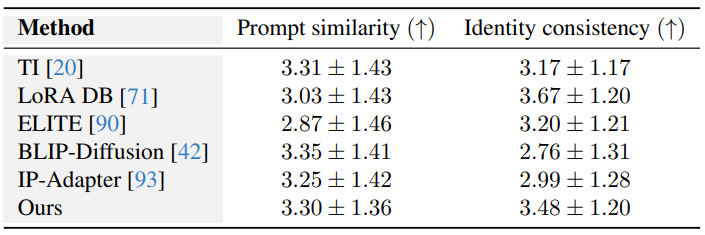
As explained in Section 4.2, we conducted a user study to evaluate our method, using the Amazon Mechanical Turk (AMT) platform [2]. We used the same generated prompts and samples that were used in Section 4.1, and asked the evaluators to rate the prompt similarity and identity consistency of each result on a Likert scale of 1–5. For ranking the prompt similarity, the evaluators were instructed the following: “For each of the following images, please rank on a scale of 1 to 5 its correspondence to this text description: {PROMPT}. The character in the image can be anything (e.g., a person, an animal, a toy etc.” where {PROMPT} is the target text prompt (in which we replaced the special token with the word “character”). All the baselines, as well as our method, were presented in the same page, and the evaluators were asked to rate each one of the results using a slider from 1 (“Do not match at all”) to 5 (“Match perfectly”). Next, to assess identity consistency, we took for each one of the characters two generated images that correspond to different target text prompts, put them next to each other, and instructed the evaluators the following: “For each of the following image pairs, please rank on a scale of 1 to 5 if they contain the same character (1 means that they contain totally different characters and 5 means that they contain exactly the same character). The images can have different backgrounds”. We put all the compared images on the same page, and the evaluators were asked to rate each one of the pairs using a slider from 1 (“Totally different characters”) to 5 (“Exactly the same character”).
We collected three ratings per question, resulting in 1104 ratings per task (prompt similarity and identity consistency). The time allotted per task was one hour, to allow the raters to properly evaluate the results without time pressure. The means and variances of the user study responses are reported in Table 1.
In addition, we conducted a statistical analysis of our user study by validating that the difference between all the conditions is statistically significant using Kruskal-Wallis [40] test (p < 1e−28 for the text similarity test and p < 1e−76 for the identity consistency text). Lastly, we used Tukey’s honestly significant difference procedure [83] to show that the comparison of our method against all the baselines is statistically significant, as detailed in Table 2.
B.4. Applications Implementation Details
In Section 4.4, we presented three downstream applications of our method.
Story illustration. Given a long story, e.g., “This is a story about Jasper, a cute mink with a brown jacket and red pants. Jasper started his day by jogging on the beach, and afterwards, he enjoyed a coffee meetup with a friend in the heart of New York City. As the day drew to a close, he settled into his cozy apartment to review a paper”, one can create a consistent character from the main character description (“a cute mink with a brown jacket and red pants”), then they can generate the various scenes by simply rephrasing the sentence:
-
“[v] jogging on the beach”
-
“[v] drinking coffee with his friend in the heart of New York City”
-
“[v] reviewing a paper in his cozy apartment”
Local image editing. Our method can be simply integrated with Blended Latent Diffusion [5, 7] for editing images locally: given a text prompt, we start by running our method to extract a consistent identity, then, given an input image and mask, we can plant the character in the image within the mask boundaries. In addition, we can provide a local text description for the character.
Additional pose control. Our method can be integrated with ControlNet [97]: given a text prompt, we first apply our method to extract a consistent identity Θ = (θ, τ ), where θ are the LoRA weights and τ is a set of custom text embeddings. Then, we can take an off-the-shelf pre-trained ControlNet model, plug-in our representation Θ, and use it to generate the consistent character in different poses given by the user.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.