
Author:
(1) David Novoa-Paradela, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain & Corresponding author (Email: david.novoa@udc.es);
(2) Oscar Fontenla-Romero, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain (Email: oscar.fontenla@udc.es);
(3) Bertha Guijarro-Berdiñas, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain (Email: berta.guijarro@udc.es).
Table of Links
4. Evaluation
In this section several experiments are presented to show the behavior of the proposed pipeline in real scenarios. The section is divided into two parts: the evaluation of the anomaly detection task (Section 4.1), and the evaluation of explanations (Section 4.2). In the first one, the capability of the pipeline to detect anomalous reviews will be evaluated using products from the Amazon platform. The second part will discuss the problems of evaluating explanations and will present a study involving humans to assess the benefits of adopting such explanations.
4.1. Evaluating the anomaly detection task
The anomaly detection task that solves the proposed pipeline can be evaluated following the usual methodology in the field of anomaly detection. In this first part of the evaluation we will describe the test scenario used, the methodology employed, and we will discuss the results obtained.
4.1.1. Experimental setup
The objective of this study is to evaluate the capacity of the pipeline in a real anomaly detection scenario. Although Section 3.2 defines the requirements for the anomaly detection methods that the pipeline can use, in these tests different alternatives have been compared. Specifically, two noniterative implementations of autoencoder networks and a boundary-based method have been employed. These methods are DAEF [26], OS-ELM [38], and OC-SVM [39] respectively.
For the evaluation, we employed datasets obtained from the large Amazon database [8], which collects reviews of various products from the year 1996 to 2018. The main problem with this dataset is that the reviews that compose it are not labeled as normal or anomalous. Because of this, in order to simulate a scenario similar to the one described throughout the article, we have decided to select the reviews corresponding to several of the most demanded products. Thus, for a given test we could consider the reviews of one product as normal, and introduce reviews from other products as anomalous. Five different product categories were selected, for which the two products with the highest
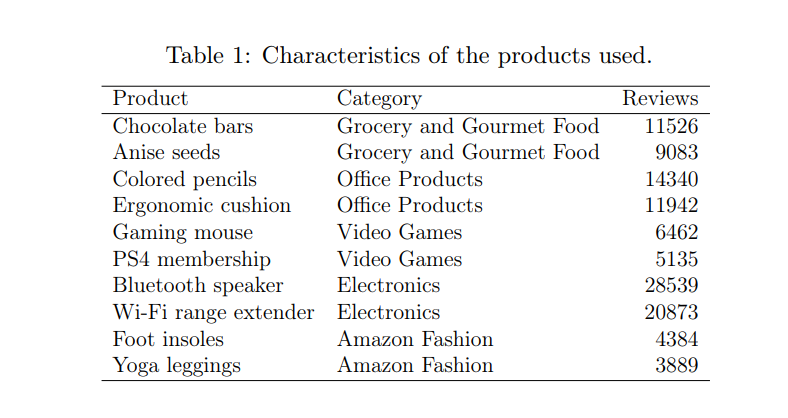
number of reviews were used, resulting in a total of 10 products. Table 1 summarizes its characteristics. In all cases, MPNet was used as the model to encode the text reviews.
Besides we considered two types of tests based on the products used:
• 1vs.4 - Far products: For each of the five categories, in this type of tests the product with the most reviews from one of the categories will be considered as the normal class, while the product with the highest number of reviews from each of the other four categories will be considered as the anomalous class. The fact that the product considered normal belongs to a different category should facilitate its distinction.
• 1vs.1 - Near products: For each of the five categories, in these tests the two products with the most reviews of the same category will be selected. One will be considered as the normal class and the other as the abnormal class. The fact that both products belong to the same category should make it more difficult to distinguish them since they may have common characteristics.
The anomaly detection algorithms were trained using only normal data (the product considered as normal), while the test phase included data from both classes in a balanced manner (50% normal and 50% anomalies).
To evaluate the performance of each algorithm with each combination of hyperparameters a 10-fold has been used. The normal data were divided into 10-folds so that, at each training run, 9 folds of normal data were used for training, while the remaining fold and the anomaly set were used together in a balanced manner for testing.
In this work, reconstruction errors at the output of the anomaly detector were calculated using Mean Squared Error (MSE). To establish the threshold above which this error indicates a given instance corresponds to an anomaly, among the various methods available, we employed a popular approach based on the interquartile range (IQR) of the reconstruction errors of the training examples, defined by:

4.1.2. Evaluating the anomaly detection task
Table 2 shows the results of the 1vs.4 - Far products test. As can be seen, the performance of the three models is remarkable, highlighting that obtained by the OS-ELM autoencoder network. We can affirm that the embeddings produced by the MPNet model provide an encoding with sufficient quality for the anomaly detection models to be able to differentiate between the evaluated products.
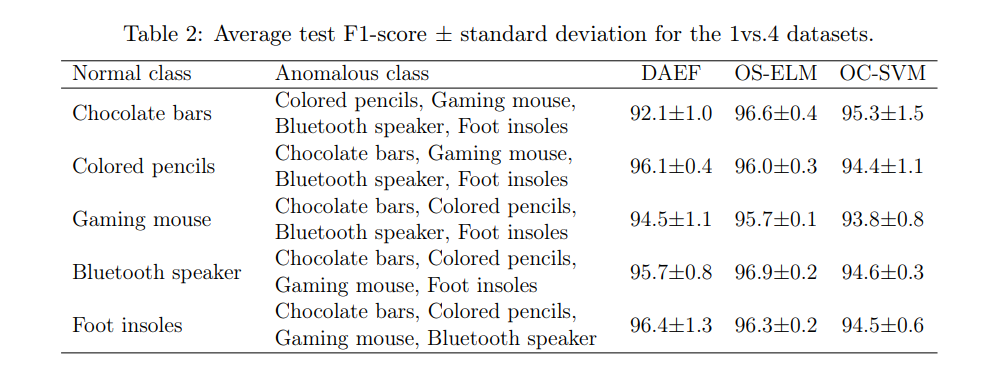
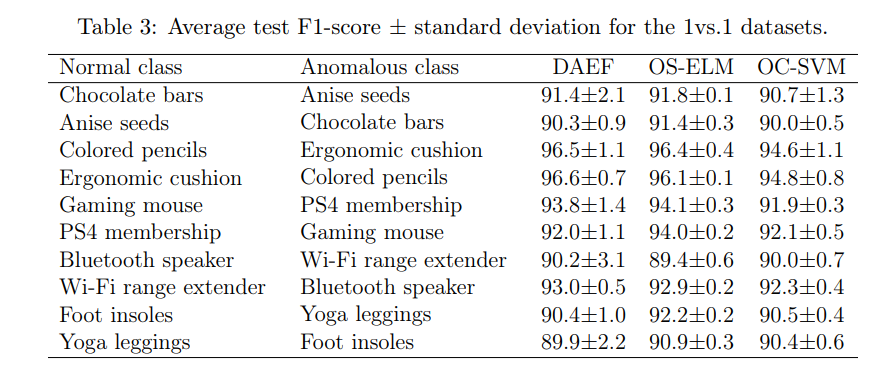
Table 3 collects the results of test 1vs.1 - Near products. As can be seen, the overall performance is still good, although it has been slightly reduced concerning the previous test, possibly because the task is a little more complicated as the products are closer together. Nevertheless, once again, the quality of the embeddings allows a proper differentiation between products.
4.2. Evaluating the explanations for model classifications
In Section 3.3, we proposed as a method of explanation to support the model decisions one based on the occurrence of frequent terms, based on the hypothesis that normal reviews will tend to use certain terms regularly, while anomalous reviews will not. In this section, this approach is compared, qualitatively through user surveys, with two other popular alternative approaches to achieve such explainability, specifically SHAP [40] and GPT-3 [32].
4.2.1. Explanations based on SHAP
Many explainability techniques base their operation on determining which characteristics of the dataset have most influenced the predictions. For example, in industrial scenarios, it is common for the features of the datasets to come directly from the physical aspects measured by the sensors of the machines, giving rise to variables such as temperatures, pressures or vibrations. By quantifying the influence of each of these variables on the output of the system we can achieve very useful explanations.
However, in the scenario proposed in this paper, the data received by the anomaly detection model as input are the reviews’ embeddings, these being numerical vectors. The variables that make up the embeddings are not associated with aspects understandable by human beings such as temperatures or pressures, so determining which ones have influenced the most would not provide us with useful information.
To solve this problem, some explainability techniques have been adapted to deal with texts. In the case of NLP models, specifically transformers, SHAP (SHapley Additive exPlanations) [40] is one of the most widely used techniques. SHAP is a game theory-based approach to explain the output of any machine learning model. SHAP also assigns each feature an importance value for a particular prediction, but it has been extended to provide interpretability to models that use embeddings as input. In these cases, it can quantify the importance of each word of the original text in the prediction, which generates a quite understandable interpretation for a human being.
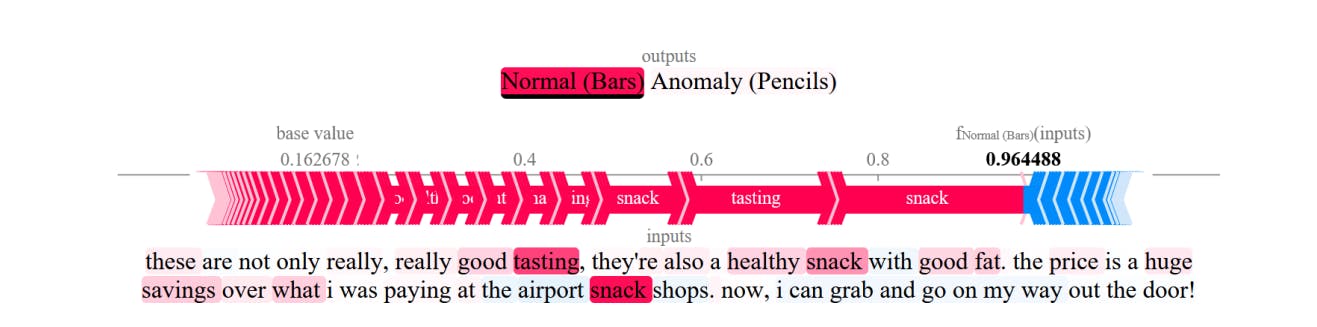
In this work, we considered that SHAP could be a good alternative to our proposal to generate the explanations associated with the classification of the reviews. Figure 3 shows the explanation generated by SHAP for a review classified as normal, where it can be seen that each term of the review has an associated score representing its influence on the classification. Despite this, for the evaluation of explanation techniques and to facilitate the understanding of the explanation by the final users, during this work (many of them unfamiliar with these techniques), the explanations generated by SHAP will be simplified, showing only the five most influential terms, instead of all.
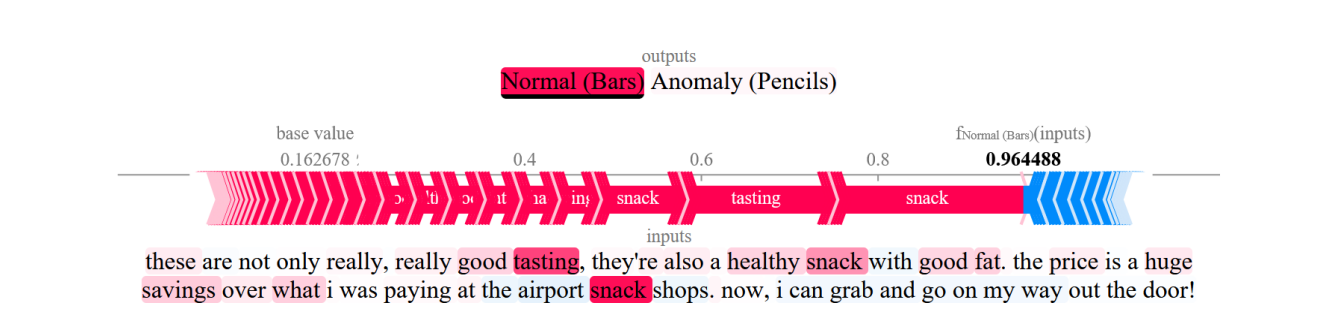
4.2.2. Explanations based on GPT-3
There is no doubt that GPT-3 has started a technological revolution at all levels. Its availability to the general public has led to the discovery of a large number of unimaginable features before its release. The original idea was to create a high-level conversational bot, trained with a large amount of text available on the web, such as books, online encyclopedias or forums. However, its deep understanding of language has far exceeded the preset idea of a chatbot. GPT-3 is capable of successfully carrying out tasks that go beyond writing a joke or summarizing a novel, GPT-3 is capable of analyzing and developing code in multiple programming languages, generating SEO positioning strategies, or carrying out NLP tasks traditionally solved by ad hoc models, such as sentiment analysis.
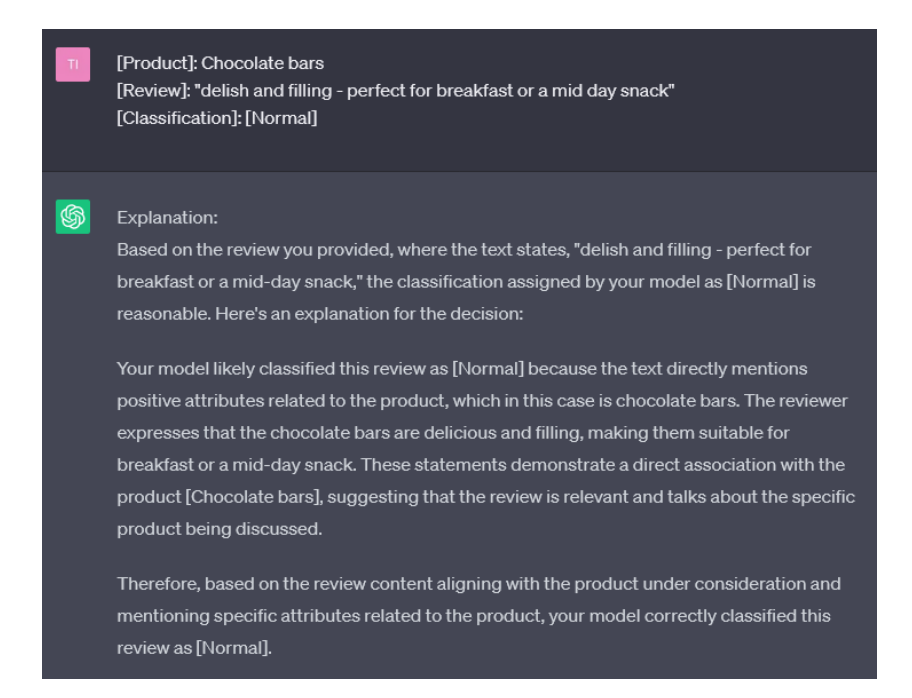
Due to its enormous potential, in this work, we have decided to study GPT-3 as an explainability model. To do this, first of all, we have introduced a prompt in which we describe the task that our anomaly detection model is carrying out, as well as the format with which we will work in future prompts (see Figure 4). After this, and following the predefined format, GPT-3 is ready to generate the explanations (see Figure 5). Although GPT3 does not have direct knowledge of the anomaly detection model, its ability to generate consistent and intuitive responses can be of great help to humans reading the explanations.

We should note that since GPT-3 trains on a wide range of data from the internet, including data that may contain biases, there is a risk that the generated explanations may reflect or amplify those biases. It is essential to exercise caution and perform a critical analysis of the explanations generated, considering their context and possible inherent biases.
4.2.3. How to evaluate explainability
Unlike other tasks such as anomaly detection, the quality of the explanations generated to provide certain interpretability to a model is not easily measurable. In a scenario like the one described in this paper, the subjectivity of the users plays a strong role when determining whether an explanation is appropriate or not. Due to this, we have decided to carry out a comparative study of the three explainability techniques by means of a survey. This survey was disseminated through the students, professors, and research and administrative staff of our university, giving rise to a total of 241 participants. Table 4 shows the number of participants by area of knowledge. To build the survey, reviews from the “1 vs. 4” scenario described in Table 2 were used, considering “chocolate bars” as the normal class, and DAEF as an anomaly detection method.

The survey consists of two different tests: (1) Forward simulation [41], which allows measuring the effect of explanations on users; (2) Personal utility, which allows measuring the utility of the explanations based on the personal preferences of the users.
4.2.4. Forward simulation
This test is inspired by the work carried out by P. Hase et al. [41] and is divided into four phases: a Learning phase, a Pre-prediction phase, a Learning phase with explanations, and a Post-prediction phase. To begin, users are given 20 examples from the model’s validation set with reviews and model predictions but no explanations. Then they must predict the model output for 10 new reviews. Users are not allowed to reference the learning data while in the prediction phases. Next, they return to the same learning examples, now with explanations included. Finally, they predict model behavior again on the same instances from the first prediction round. The classes of reviews chosen for each of the phases described are balanced between normal and abnormal. By design, any improvement in user performance in the Post prediction phase is attributable only to the addition of explanations that help the user to understand the model behaviour.

Figure 6 represents this procedure, where x represents a review, yb is the class predicted by the model, and y˜ the class predicted by the human simulation. Taking this into account, the Explanation Effect can be calculated as follows:
Explanation Effect = Post Accuracy − P re Accuracy (5)
where the pre and post accuracies area calculated comparing the user’s prediction against the model’s prediction. In order not to bias the results, we have decided that each person surveyed will only participate in the forward simulation of a single explainability technique, so that the total number of participants was divided randomly into three groups, each one associated with one of the three techniques: Terms frequency (78), SHAP (89), and GPT-3 (77). The three groups of participants will deal with the same reviews throughout the four phases of the test, only the explanations presented in the third phase of the test (learning with explanations) will vary depending on the assigned group/technique. Throughout the survey, we have warned users several times that they should try to simulate the behavior of the anomaly detection model, instead of ranking the reviews using their personal criteria.
Tables 5 and 6 show the results of this test. As can be seen in the first table, the average explanation effect of the three explainability techniques has not been very remarkable. The high standard deviation suggests a high variability between the different study participants, both in the initial (Pre) and subsequent (Post) classifications and therefore in the explanation effect. The initial difference between the groups in the Pre-accuracy and the closeness of the three techniques in the explanation effect does not allow us to opt for any of the three options.
In Table 6 we can see the results of the test based on the area of knowledge of the participants. The results obtained using the different explainability techniques have been aggregated. The purpose of this comparison is to analyze whether there is any relationship between the technical background of the respondents and their performance on the test. As can be seen, there are slight differences between the values of pre and post accuracy, with the group of respondents belonging to the area of natural sciences standing out, whose explanation effect was the only positive one (4.5%).
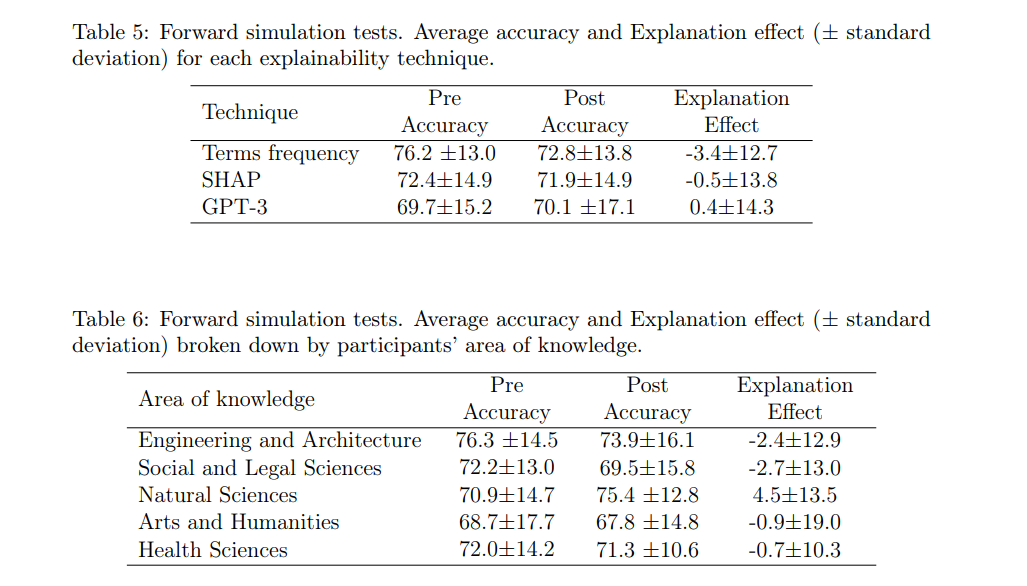
Analyzing the results we can affirm that the initial accuracy (pre-accuracy) is quite high, which indicates that the respondents tend to successfully reproduce the behavior of the model even if they do not have the explanations. This could be because, in this case, both the input data to the AD model (in natural language) and the problem it solves are easily understandable to a human, which means that the respondents are able to solve the classification problem by themselves. The standard deviation accompanying the pre-accuracy results is notable but does not become too high, which reaffirms the previous argument.
After supplying the respondents with the explanations associated with the reviews, the post-accuracy obtained by them presents values very similar to the previous scores (pre-accuracy). We can therefore affirm that in general terms the effect of the explanations, in this case, has not been beneficial for the users during this test.
The non-improvement may be due to several reasons. One of them may be the presence of reviews that show a certain degree of ambiguity, which not only makes their classification difficult for the respondents, but also for the AD models. However, in real scenarios the occurrence of reviews whose normality score is around the threshold value would be something to be expected, not all events are easily classifiable. Another possible reason may be that the tendency of some users throughout the survey has been to classify the reviews using their personal criteria, rather than trying to simulate the behavior of the anomaly detection model.
4.2.5. Personal utility
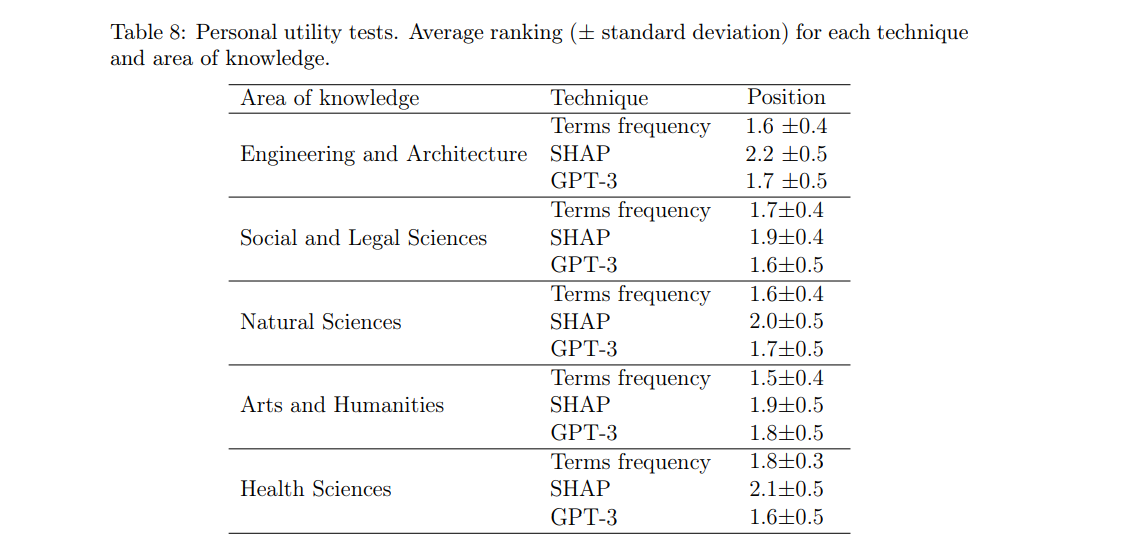
After completing the first test, the participants were given a second exercise, common to all participants, regardless of the group to which they were assigned in the previous phase. This consists of a subjective evaluation of the three explainability techniques. The idea is to present the participant with a review, its classification by the model, and an explanation generated by each of the three explainability techniques. The participant must order the explanations based on how useful it is to understand the reasoning behind the model’s decision (ties were allowed between explanations). This process was repeated with a total of eight reviews. Tables 7 and 8 show the final average rankings of the explainability techniques.
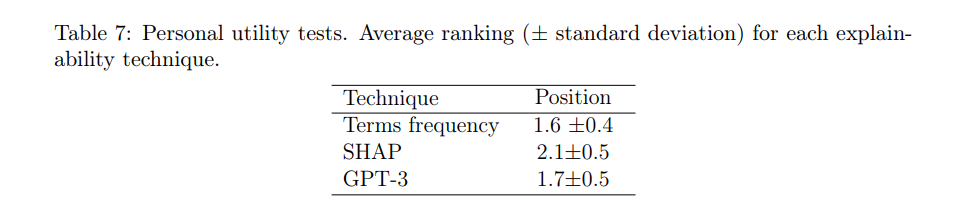
As can be seen in Table 7, the explanations based on Term frequency (1.6) and GPT-3 (1.7) are in very close positions, both being above the third method SHAP (2.1). It is possible that the preference of respondents for the first two methods is due to the fact that the format of their explanations is more accessible and descriptive for a larger part of the population. Grouping the results by areas of knowledge (Table 8), we can see that the general trend is maintained for most areas. We can highlight the case of Social and Legal Sciences and Health Sciences, areas in which the positions in the ranking of Terms frequency and GPT-3 techniques are slightly inverted, with GPT-3 being the preferred option.
This paper is available on arxiv under CC 4.0 license.