

Authors:
(1) Arindam Mitra;
(2) Luciano Del Corro, work done while at Microsoft;
(3) Shweti Mahajan, work done while at Microsoft;
(4) Andres Codas, denote equal contributions;
(5) Clarisse Simoes, denote equal contributions;
(6) Sahaj Agarwal;
(7) Xuxi Chen, work done while at Microsoft;;
(8) Anastasia Razdaibiedina, work done while at Microsoft;
(9) Erik Jones, work done while at Microsoft;
(10) Kriti Aggarwal, work done while at Microsoft;
(11) Hamid Palangi;
(12) Guoqing Zheng;
(13) Corby Rosset;
(14) Hamed Khanpour;
(15) Ahmed Awadall.
Table of Links
Teaching Orca 2 to be a Cautious Reasoner
B. BigBench-Hard Subtask Metrics
C. Evaluation of Grounding in Abstractive Summarization
F. Illustrative Example from Evaluation Benchmarks and Corresponding Model Outpu
A AGIEval Subtask Metrics
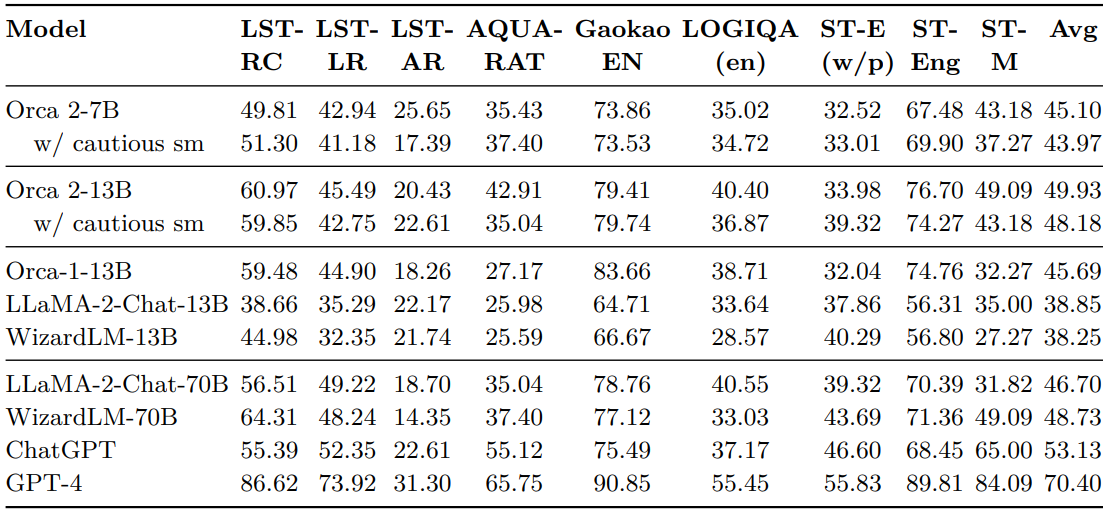
AGIEval contains several multiple-choice English tasks. Table 6 provides the performance of Orca 2 and baseline models on each individual AGIEval tasks. The task performance is gauged using exact match accuracy, adhering to the methodology laid out in [69].
Orca 2 model Insights:
• The 13B variants of Orca 2— both with empty and cautious system message — deliver competitive results. The Orca-2-13B w/ cautious sm achieves an average score of 48.18%, whereas the Orca-2-13B records an average of 49.93%.
• The 7B iterations, although surpassed by their 13B counterparts, still achieve relatively competitive scores, with averages of 45.10% and 43.97% for the empty and cautious strategies, respectively.
Outperforming Other State-of-The-Art Benchmarks:
• LLaMA-2-Chat-13B: On average, Orca-2-13B outperforms LLaMA-2-Chat-13B by +11.08 points. Specifically, the Orca 2 model holds a noticeable lead in tasks like LSAT-RC (+22.31 points), LSAT-LR (+10.20 points), and Gaokao EN (+14.70 points).
• WizardLM-13B: Orca-2-13B surpasses WizardLM-13B by +11.68 points on average. In individual tasks, Orca 2 holds a significant advantage in LSAT-RC (+15.99 points) and Gaokao EN (+12.74 points).
• LLaMA-2-70B: Overall,Orca-2-13B leads LLaMA-2-70B by +3.23 points on average. This is particularly interesting as Orca 2 has around 5X less parameters. For specific tasks, Orca-2-13B lags behind in LSAT-LR (-3.73 points), LOGIQA (-0.15) and SAT-English (w/o Psg.) (-5.34), but it does better in the rest, notably AQUA-RAT (+7.87 points) and SAT-MATH (+17.71).
Benchmarking vs. Orca1:
• In most tasks, Orca 2 models surpass Orca1.
• LSAT-LR: Orca-2-13B w/ cautious sm trails by -2.15 points but Orca-2-13B outperforms by +0.59.
• GAOKAO-EN: Orca-2-13B and Orca-2-13B w/ cautious sm fall short by -3.92 and -4.25 points respectively.
• In LOGICQA (en) Orca-2-13B w/ cautious sm lags by -1.84 while SAT English it does by -0.49.
• In all other cases Orca 2-13B outperforms Orca-1-13B predecesor. On average: Orca 2 with cautious system message leads Orca1 by +2.49 points, and Orca-2-13B does so by +4.24 points.
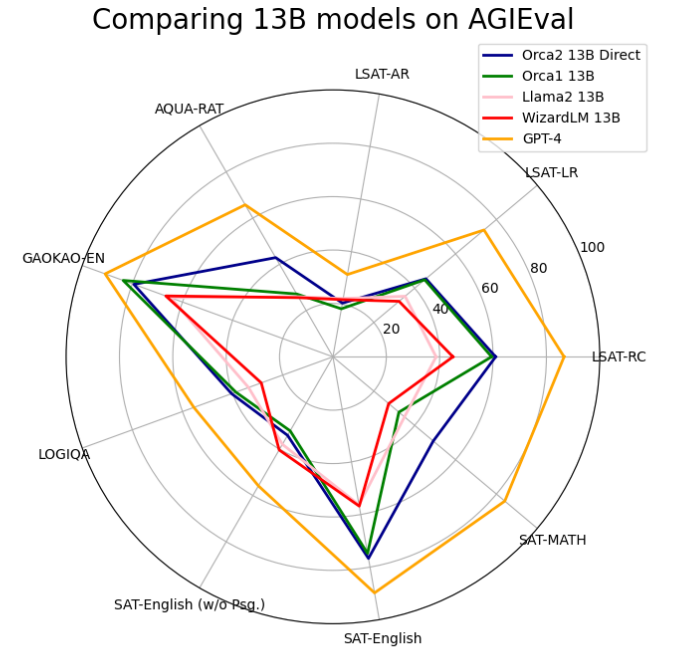
To wrap up, the Orca 2 models show a notable progression in performance for zero-shot reasoning tasks, surpassing models as large as 70B parameters. This represents a significant step forward from their predecessor, Orca-1-13B. For a visual representation Figure 13 illustrates the comparative results between Orca 2 empty system message and other baselines.
This paper is available on arxiv under CC 4.0 license.