

Authors:
(1) Dinesh Kumar Vishwakarma, Biometric Research Laboratory, Department of Information Technology, Delhi Technological University, Delhi, India;
(2) Mayank Jindal, Biometric Research Laboratory, Department of Information Technology, Delhi Technological University, Delhi, India
(3) Ayush Mittal, Biometric Research Laboratory, Department of Information Technology, Delhi Technological University, Delhi, India
(4) Aditya Sharma, Biometric Research Laboratory, Department of Information Technology, Delhi Technological University, Delhi, India.
Table of Links
- Abstract and Intro
- Background and Related Work
- EMTD Dataset
- Proposed Methodology
- Experiments
- Conclusion and References
4. Proposed Methodology

4.1. Descriptions
Movie plot/descriptions are an important feature to describe a movie. In most cases, the plot mentioned for a movie being released is either too short or not mentioned in some cases. Considering this, we choose to use the descriptions concatenated with the dialogues extracted from movie trailers to finally predict the movie genre, as discussed in Section 4.2 in detail. Descriptions are fetched from the IMDB website as metadata as already mentioned in Section3.
4.2. Dialogue
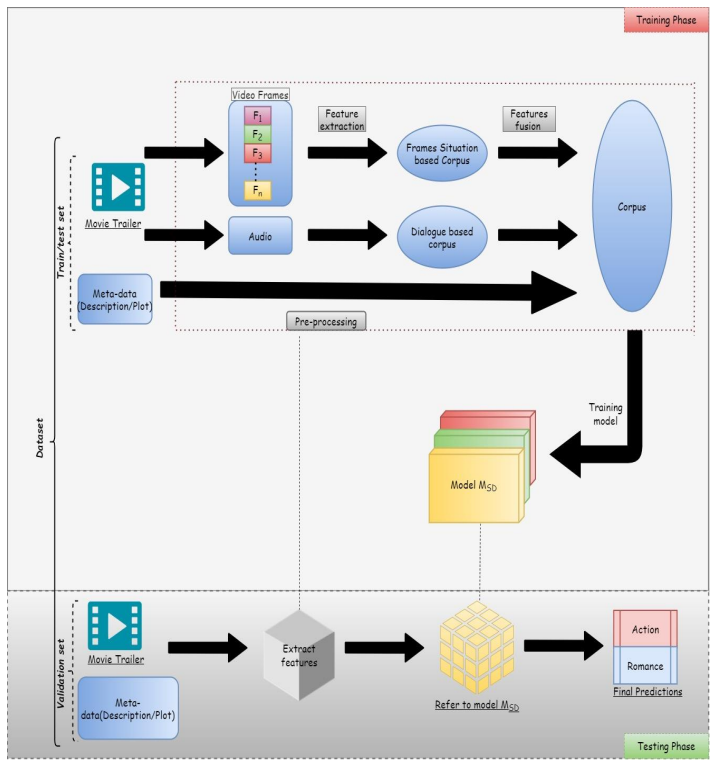
In this section, we propose an architecture to process a list of dialogues from the trailer’s audio (concatenated description/plot to dialogues) to predict movie genres. Significant steps for this stream include: (1) Extract speech (dialogue) from movie trailer and (2) Design a model to predict genres on the basis of speech and metadata.
4.2.1. Data pre-processing
The audio files in (.wav) format are extracted from the (.mp4) video trailers. Next, the audio file is split into small audio clips and converted to dialogues as proposed in [17]. All the text is collected to form an input corpus. Description/plot (if available in metadata) is also merged to this corpus. Our study is targeted for the English language trailers only. Just like movie plots, the speech extracted from the trailers can work as a supplement to our text corpus, which can help in better understanding of the relation between the text context and the genre of the movie. After generating the corpus comprised of a single record for each trailer in our training/testing phase the following pre-processing steps were conducted: converting all the text to lowercase, eliminating digits, punctuations, stop-words, and web-links. Text obtained above is used to feed as an input to the model/pre-trained model for training/testing.
4.2.2. Feature Extraction (Dialogue)


4.2.3. ECnet (Embedding – Convolution network)
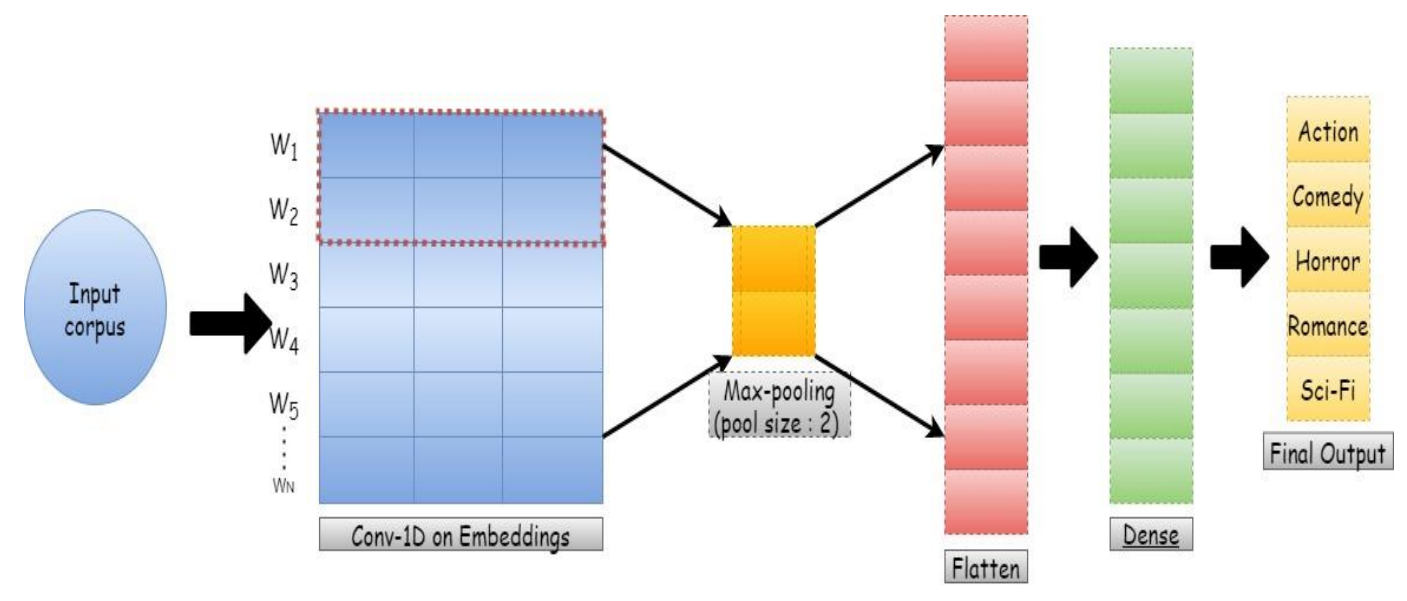
To build cognitive-based genre detection architecture, the crucial features of the trailer in the form of a text corpus needs to be learned by a model. This can be achieved by using a combination of Embedding and CNN (Convolution Neural Network) layers. The layers of the multi-label classification network is depicted in Table 3. Embedding is one of the popular techniques used in NLP problems for converting words into mathematical representation in the form of numerical vectors.
Before actually sending input to the architecture, the vocabulary needs to be designed and the size of a corpus for each data point needs to be fixed. A vocabulary of size 10,395 words is designed and the maximum length of the number of words in each corpus is set to be the length of the longest sentence in our training corpus, which is 330 in our case. If the number of words in a corpus is less than the max length, the corpus is padded with 0’s. For a 2-3-minute movie trailer, 330 words are found to be sufficient as in some parts of the trailer there may be no speech (only vocals might be present).
Now for each corpus in the input data, we are having an input of shape (330,) (330 is the number of words in each data point), which is fed to the first layer of our architecture as in Fig. 2, i.e., embedding layer. The embedding layer gives an output of dimension (330, 64,) as the length of embedding for each word is taken to be 64 in our proposed architecture.
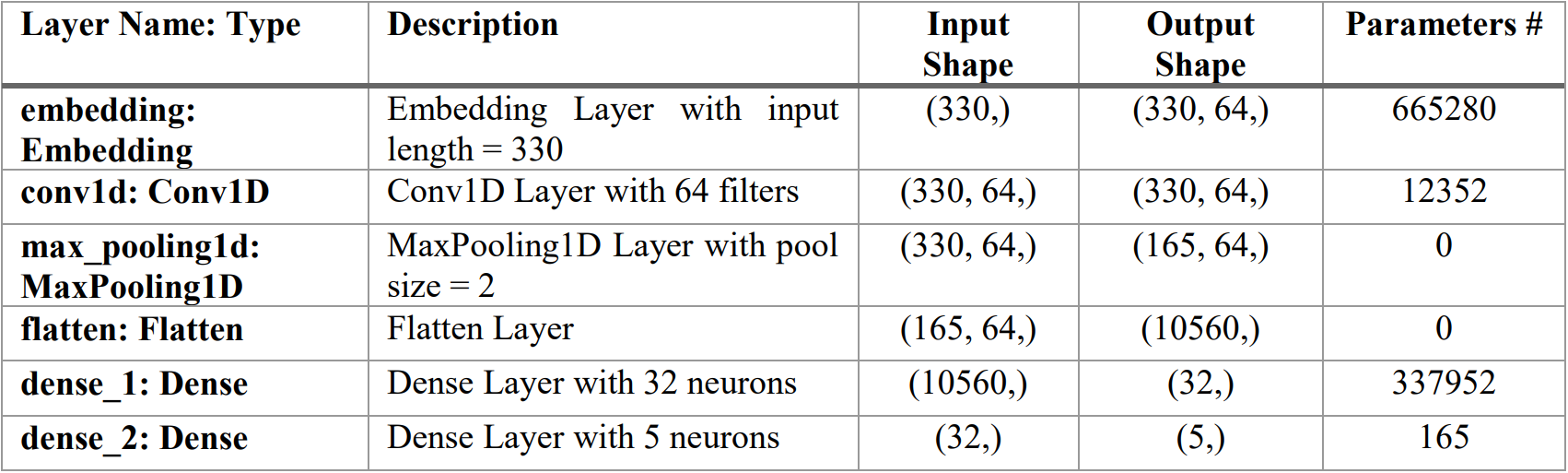
After the embedding layer, a 1-D convolution layer is fed with the output of the embedding layer. Again, the convolution layer gives an output shape of (330, 64,). To get the same output, we apply the padding uniformly to the input of the convolution layer. Next, a max-pooling layer is used to reduce the dimension of data from (330, 64,) to (165, 64,). The architecture is followed by a flatten layer to transform the two-dimensional data into one-dimensional data, to further send the output to a dense layer.
As depicted in Table 3, the flatten layer gives an output of shape (10560,) which is fed to a dense layer as input and giving an output shape of (32,). Finally, the final dense layer is applied to the architecture returning the output shape of (5,) denoting our five genres. In our architecture's final dense layer, we use “sigmoid” as an activation function best suited for our multi-label classification problem.
4.3. Situation
This section includes the work we proposed on visual features from movie trailers. Primary steps for this stream include: (1) fetch video frames from the trailer, (2) extract situations from the frames and (3) build architecture to finally classify the trailers into genres.
A novel situation-based video analysis model is proposed by extracting the situations and events based on each frame extracted from the video for visual features. Thus, a corpus is created to train/test the model by collecting them together.
To the best of our knowledge, we are proposing a novel framework by fusing the situation, event, and dialogue analysis for genre classification. More details about the framework are described in the below sections.
4.3.1. Frame Extraction from Video
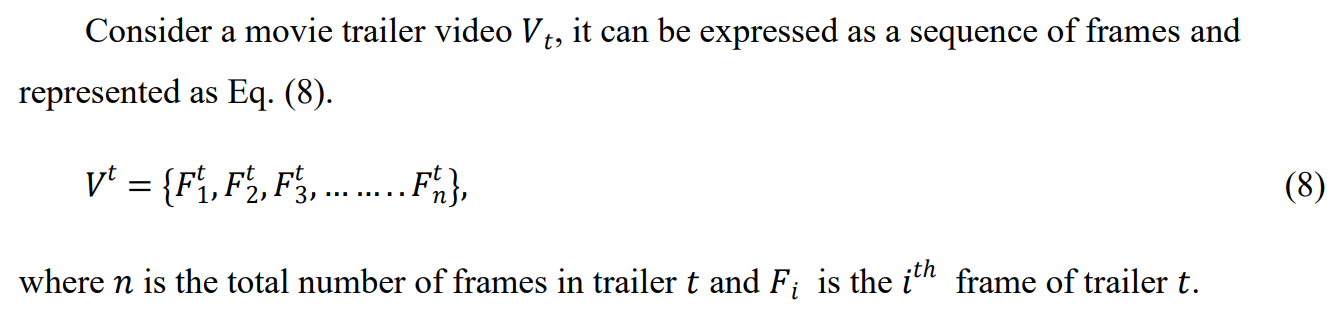
After various experimentation using some subset of movie trailers, it is found that taking every 10𝑡ℎ the frame is beneficial to avoid redundancy in frames (consecutive frames from a video appear to be similar). Hence, after discarding the redundant frames, the final video frames considered can be expressed as Eq. (9):

In the subsequent sections, we consider these frames for every trailer.
4.3.2. Feature Extraction (Situation)



And the probability that situation S belongs to an image I can be denoted as in Eq. (11).

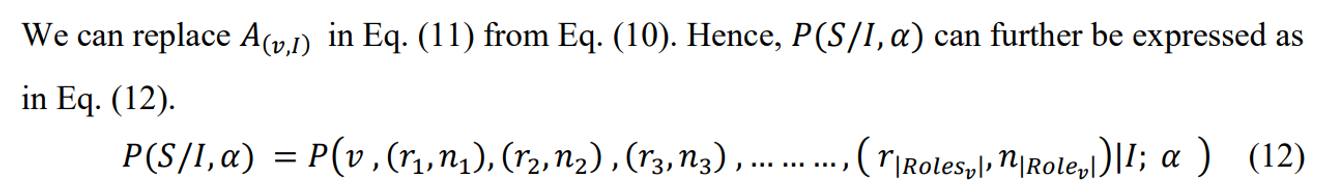
𝛼 denotes the parameter for our neural; network. Now, we can define the semantic roles in an image in a particular order. Thus further, the Eq. (12) be reduced to Eq. (13).

Eq. (13) can be further simplified as Eq. (14).
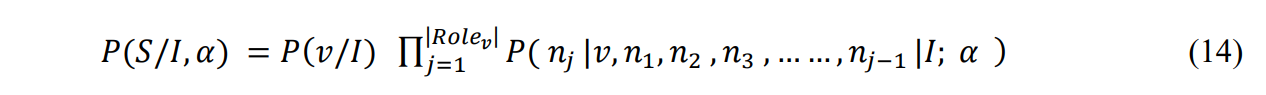
For a given particular image/frame, the situation having maximum value probability defined in Eq. (14) will be considered for that image.

Now the task is converted to a text classification task for which we propose the model architecture as discussed in upcoming sections. Before proceeding to the next step, text preprocessing is conducted: converting all the text to lowercase, eliminating digits, punctuations, and stop-words, as mentioned in Section 4.2.1. These same steps are performed in the testing procedure to predict the movie trailer genre.
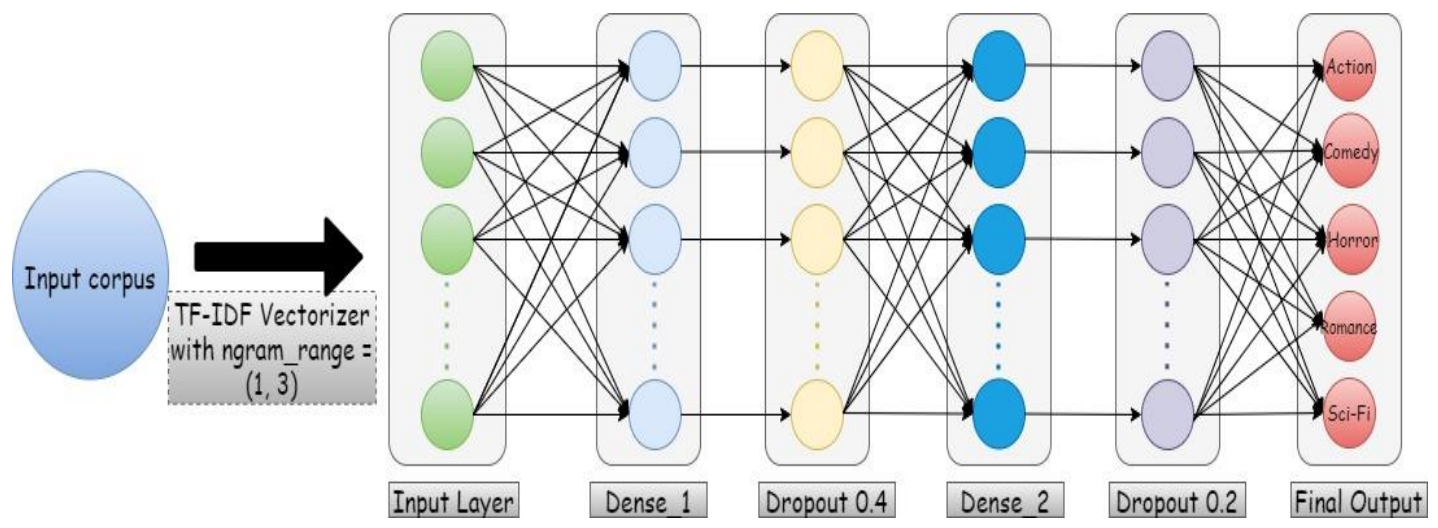
4.3.3. TFAnet (Term Frequency Artificial Neural Network)
After extracting visual features, a robust architecture is required to classify the final genres for the trailers. This model is different from the model we proposed in the dialogue stream. Here, TFAnet (Term Frequency Artificial Neural Network) is proposed consisting of a deep network of dense and dropout layers as depicted in Fig. 4.
Before coming to the proposed architecture, we will discuss the text representation using TF-IDF in [19]. For this architecture, it is proposed to use in the word count in the corpus of each data point. Hence, we use the word count from the corpus as features for classifying the movie trailer genres. In order to get a large number of words included as features in our vocabulary set, trailers from a large range of released dates are used in our EMTD to get a huge corpus available with us while training the model. A combination of unigrams, bigrams and trigrams is used from our corpus as the features and TF-IDF (term frequency-inverse document frequency) algorithm represents our text in a numerical form. The total n-grams features taken are around 34,684. Now our text-based features are transformed into mathematical form, so next (artificial neural network) is trained to classify the genres of the trailer.
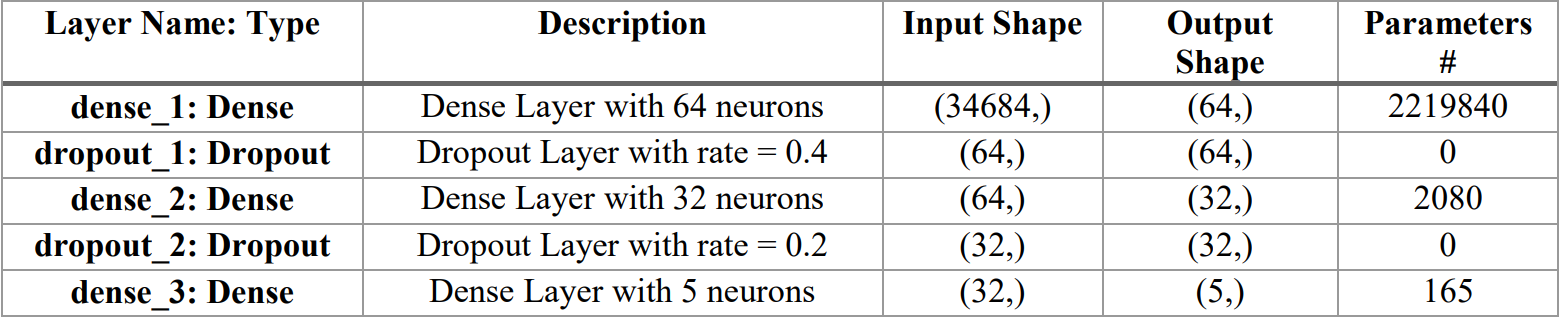
The architecture of TFAnet (Term Frequency Artificial Neural Network) is depicted in Table 4. The input shape, as discussed above, is (34684,). This input is given to a dense layer, which gives an output of shape (64,). Then a dropout layer is applied to reduce overfitting with a rate of 0.4. Again, a dense layer is applied, and we obtain an output of shape (32,), followed by a dropout layer with a rate of 0.2. Finally, a dense layer is applied, which gives an output of shape (5,) to finally predict five genres, with sigmoid as an activation function.
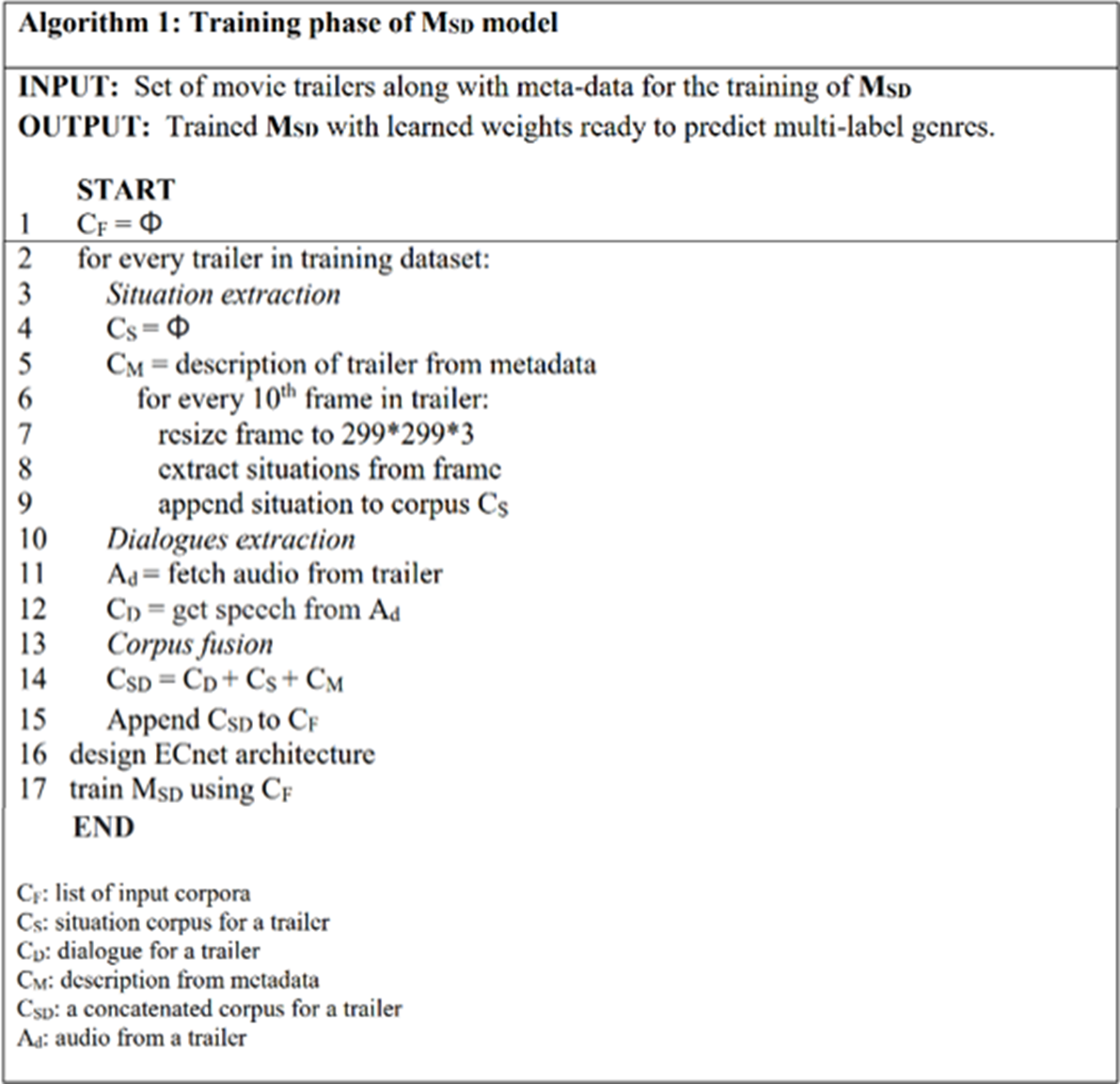
The algorithm of the training phase of MSD model is written as Algorithm 1.



This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.