

We are still amazed at the number of customers who come to us looking to migrate from HDFS to modern object storage such as MinIO. We thought by now that everyone had made the transition, but every week, we speak to a major, highly technical organization that has decided to make the transition.
Quite often, in those discussions, there are elements of their infrastructure that they want to maintain after their migration. There are frameworks and software that came out of the HDFS ecosystem that have a lot of developer buy-in and still have a place in the modern data stack. Indeed, we’ve often said that a lot of good has come out of the HDFS ecosystem. The fundamental issue is with the closely coupled storage and compute not necessarily with the tools and services that came from the Big Data era.
This blog post will focus on how you can make that migration without ripping out and replacing tools and services that have value. The reality is that if you don’t modernize your infrastructure, you can't make the advancements in AI/ML that your organization requires, but you don’t have to throw everything out to get there.
Disaggregation of Storage and Compute with Spark and Hive
We’ve already gone through some
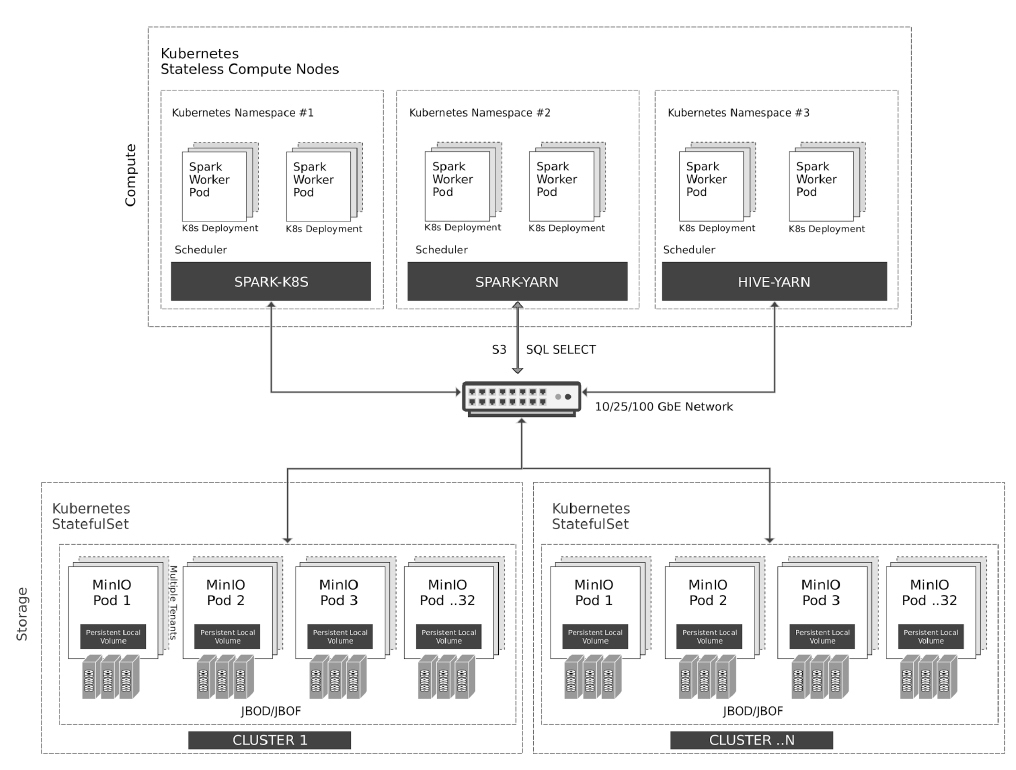
Architectural Overview:
-
Compute Nodes: Kubernetes efficiently manages stateless Apache Spark and Apache Hive containers on compute nodes, ensuring optimal resource utilization and dynamic scaling.
-
Storage Layer: MinIO
Erasure Coding and BitRot Protection means you may lose up to half of the number of drives and still recover, all without the need to maintain the three copies of each block of data that Hadoop requires. -
Access Layer: All access to MinIO object storage is unified through the S3 API, providing a seamless interface for interacting with stored data.
-
Security Layer: Data security is paramount. MinIO encrypts all data using per-object keys, ensuring robust protection against unauthorized access.
-
Identity Management: MinIO Enterprise fully integrates with identity providers such as WSO2, Keycloak, Okta, Ping Identity to allow applications or users to authenticate.
A fully modernized replacement for Hadoop that allows your organization to keep Hive, YARN and any other Hadoop ecosystem data product that can integrate with the object storage which is almost everything in the modern data stack.
Interoperability in the Access Layer
S3a is an essential endpoint for applications seeking to transition away from Hadoop, offering compatibility with a wide array of applications within the Hadoop ecosystem. Since 2006, S3-compatible object-storage backends have been seamlessly integrated into numerous data platforms within the Hadoop ecosystem as a default feature. This integration traces back to the incorporation of an S3 client implementation in emerging technologies.
Across all Hadoop-related platforms, the adoption of the hadoop-aws module and aws-java-sdk-bundle is standard practice, ensuring robust support for the S3 API. This standardized approach facilitates the smooth transition of applications from HDFS and S3 storage backends. By simply specifying the appropriate protocol, developers can effortlessly switch applications from Hadoop to modern object storage. The protocol scheme for S3 is indicated by s3a://, while for HDFS, it is denoted as hdfs://.
Benefits of Migration
It’s possible to talk at length about the benefits of migrating off of Hadoop onto modern object storage. If you’re reading this, you are already largely aware that without migration off of legacy platforms like Hadoop advances in AI and other modern data products will likely be off the table. The reason distills down to performance and scale.
There is absolutely no question that modern workloads require outstanding performance to compete with the volume of data being processed and the complexity of tasks now being required. When performance is not just about vanity benchmarking, but a hard requirement, the field of contenders for Hadoop replacements
The other element driving migrations forward is cloud-native scale. When the concept of the cloud is less of a physical location and more of an
Part and parcel of this concept is the economic benefits that come from the release from vendor lock-in, which allows an organization to pick and choose best-in-class options for specific workloads. Not to mention, the release from maintaining three separate copies of data to protect it, a thing of the past with
Getting Started
Before diving into the specifics of our architecture, you'll need to get a few components up and running. To migrate off of Hadoop, you'll obviously have had to have installed it to begin with. If you want to simulate this experience, you can start this tutorial by setting up the Hortonworks Distribution of Hadoop here.
Otherwise, you can begin with the following installation steps:
-
Set Up Ambari: Next,
install Ambari , which will simplify the management of your services by automatically configuring YARN for you. Ambari provides a user-friendly dashboard to manage services in the Hadoop ecosystem and keep everything running smoothly. -
Install Apache Spark: Spark is essential for processing large-scale data. Follow the
standard installation procedures to get Spark up and running. -
Install MinIO: Depending on your environment, you can choose between two installation approaches:
Kubernetes orHelm Chart .
After successfully installing these elements, you can configure Spark and Hive to use MinIO instead of HDFS. Navigate to the Ambari UI http://<ambari-server>:8080/ and log in using the default credentials: username: admin, password: admin,
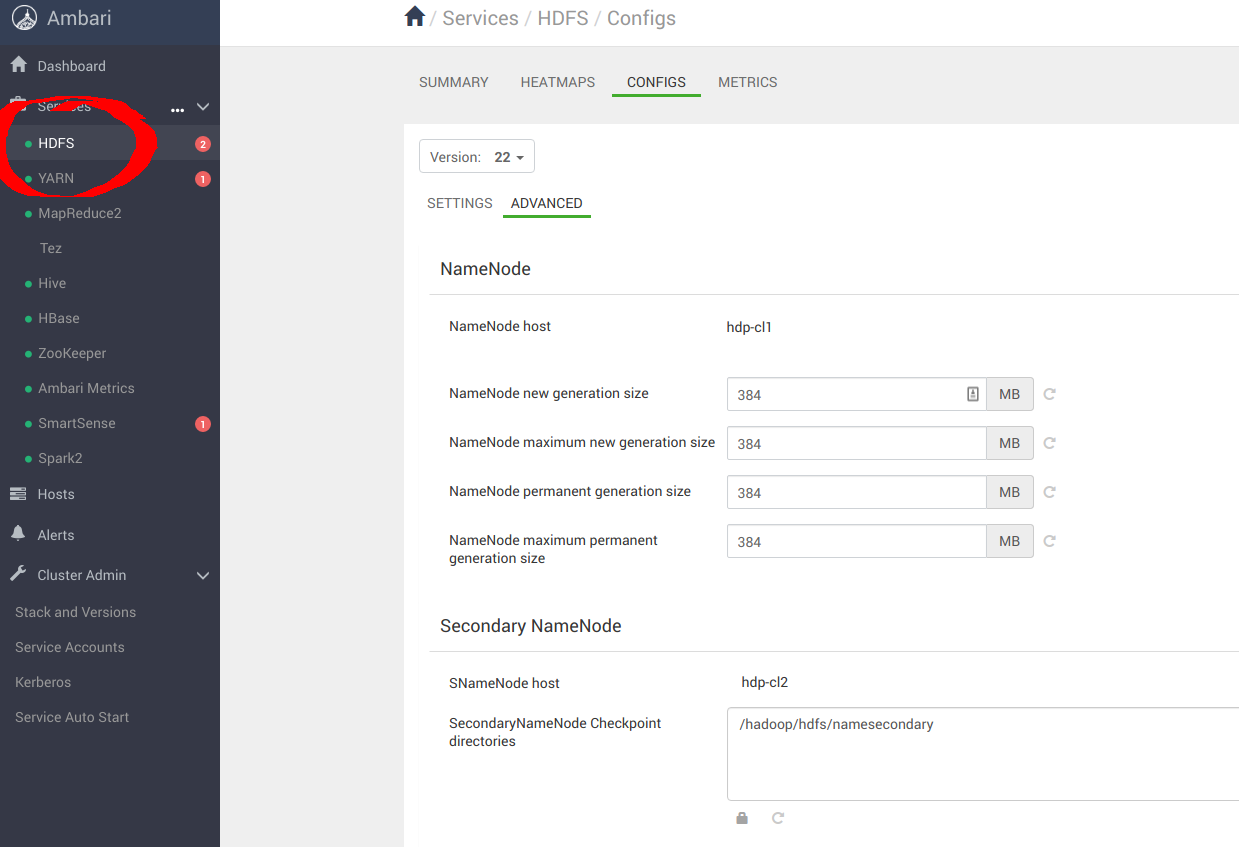
In Ambari, navigate to services, then HDFS, then to the Configs panel as in the screenshot below. In this section, you are configuring Ambari to use S3a with MinIO instead of HDFS.
Scroll down and navigate to Custom core-site. This is where you’ll configure S3a.
sudo pip install yq
alias kv-pairify='yq ".configuration[]" | jq ".[]" | jq -r ".name + \"=\" + .value"'
From here, your configuration will depend on your infrastructure. But, the below could represent a way for core-site.xml to configure S3a with MinIO running on 12 nodes and 1.2TiB of memory.
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "mapred"
mapred.maxthreads.generate.mapoutput=2 # Num threads to write map outputs
mapred.maxthreads.partition.closer=0 # Asynchronous map flushers
mapreduce.fileoutputcommitter.algorithm.version=2 # Use the latest committer version
mapreduce.job.reduce.slowstart.completedmaps=0.99 # 99% map, then reduce
mapreduce.reduce.shuffle.input.buffer.percent=0.9 # Min % buffer in RAM
mapreduce.reduce.shuffle.merge.percent=0.9 # Minimum % merges in RAM
mapreduce.reduce.speculative=false # Disable speculation for reducing
mapreduce.task.io.sort.factor=999 # Threshold before writing to drive
mapreduce.task.sort.spill.percent=0.9 # Minimum % before spilling to drive
There are quite a few optimizations that can be explored by checking out the documentation on this migration pattern
Restart All when you’re satisfied with the config.
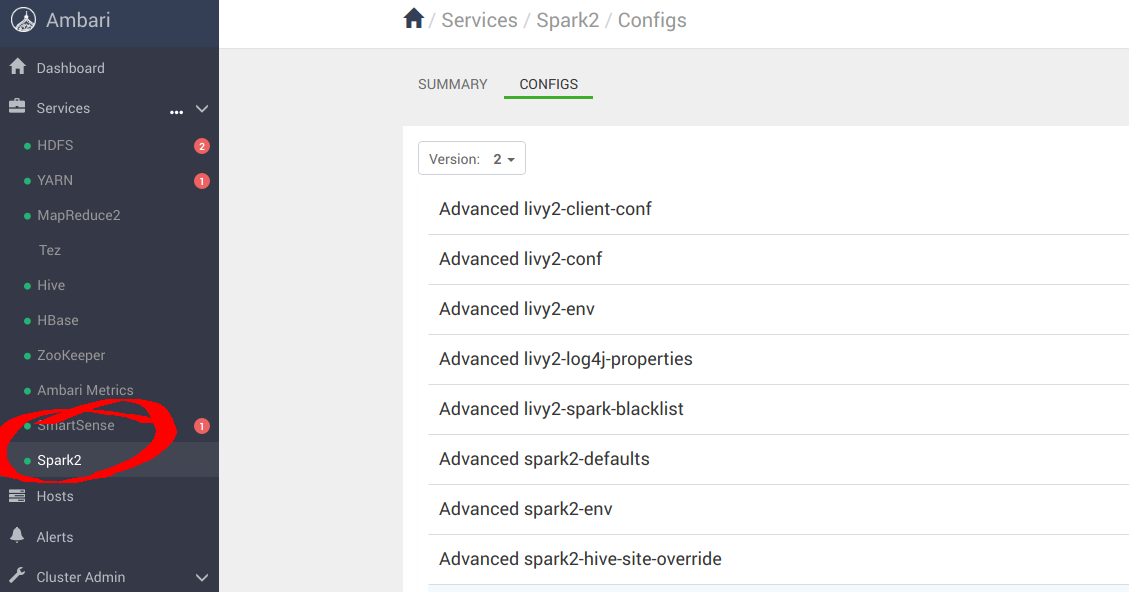
You’ll also need to navigate to the Spark2 config panel.
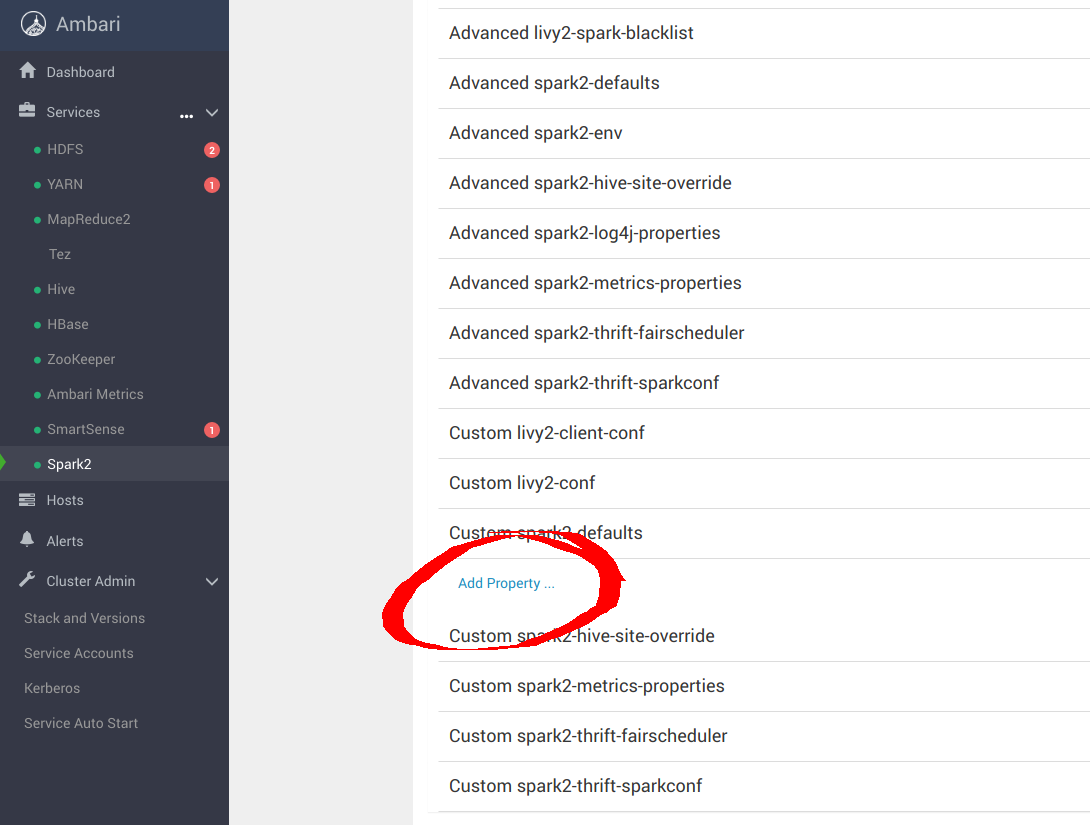
Scroll down to Custom spark-defaults and add the following Property to configure with MinIO:
spark.hadoop.fs.s3a.access.key minio
spark.hadoop.fs.s3a.secret.key minio123
spark.hadoop.fs.s3a.path.style.access true
spark.hadoop.fs.s3a.block.size 512M
spark.hadoop.fs.s3a.buffer.dir ${hadoop.tmp.dir}/s3a
spark.hadoop.fs.s3a.committer.magic.enabled false
spark.hadoop.fs.s3a.committer.name directory
spark.hadoop.fs.s3a.committer.staging.abort.pending.uploads true
spark.hadoop.fs.s3a.committer.staging.conflict-mode append
spark.hadoop.fs.s3a.committer.staging.tmp.path /tmp/staging
spark.hadoop.fs.s3a.committer.staging.unique-filenames true
spark.hadoop.fs.s3a.committer.threads 2048 # number of threads writing to MinIO
spark.hadoop.fs.s3a.connection.establish.timeout 5000
spark.hadoop.fs.s3a.connection.maximum 8192 # maximum number of concurrent conns
spark.hadoop.fs.s3a.connection.ssl.enabled false
spark.hadoop.fs.s3a.connection.timeout 200000
spark.hadoop.fs.s3a.endpoint http://minio:9000
spark.hadoop.fs.s3a.fast.upload.active.blocks 2048 # number of parallel uploads
spark.hadoop.fs.s3a.fast.upload.buffer disk # use disk as the buffer for uploads
spark.hadoop.fs.s3a.fast.upload true # turn on fast upload mode
spark.hadoop.fs.s3a.impl org.apache.hadoop.spark.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.max.total.tasks 2048 # maximum number of parallel tasks
spark.hadoop.fs.s3a.multipart.size 512M # size of each multipart chunk
spark.hadoop.fs.s3a.multipart.threshold 512M # size before using multipart uploads
spark.hadoop.fs.s3a.socket.recv.buffer 65536 # read socket buffer hint
spark.hadoop.fs.s3a.socket.send.buffer 65536 # write socket buffer hint
spark.hadoop.fs.s3a.threads.max 2048 # maximum number of threads for S3A
Restart all after the config changes have been applied.
Navigate to the Hive panel to finish up the configuration.
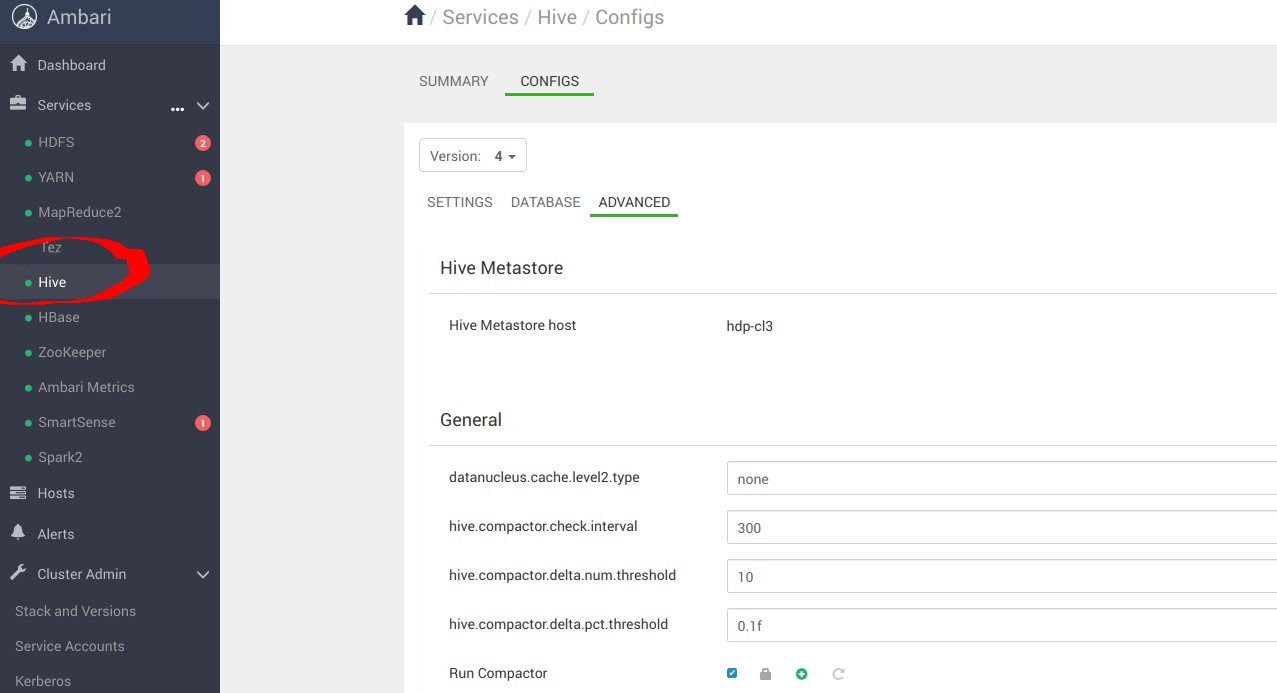
Scroll down to Custom hive-site and add the following Property:
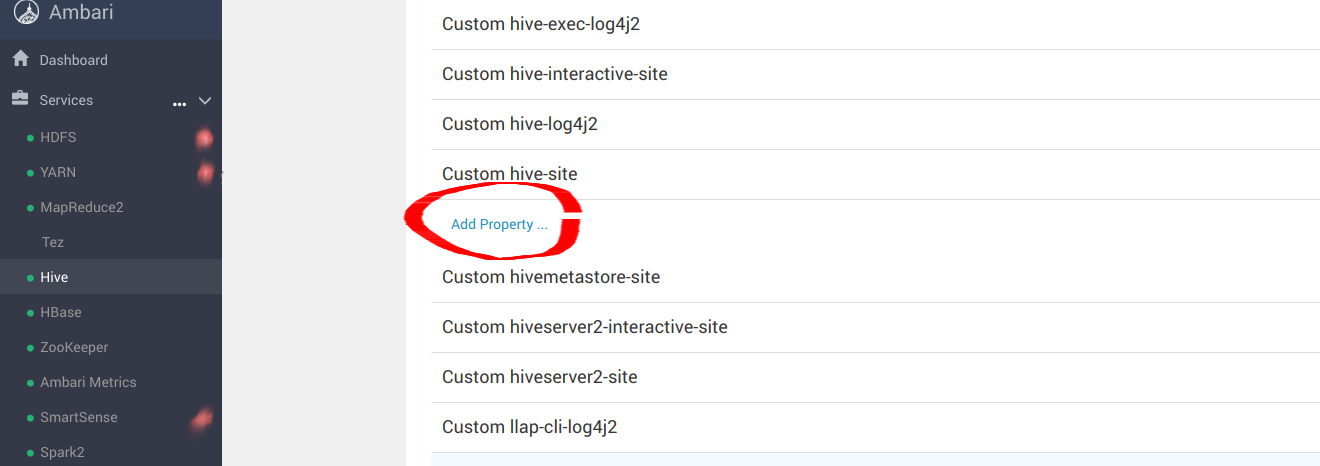
hive.blobstore.use.blobstore.as.scratchdir=true
hive.exec.input.listing.max.threads=50
hive.load.dynamic.partitions.thread=25
hive.metastore.fshandler.threads=50
hive.mv.files.threads=40
mapreduce.input.fileinputformat.list-status.num-threads=50
You can find more fine-tuning configuration information
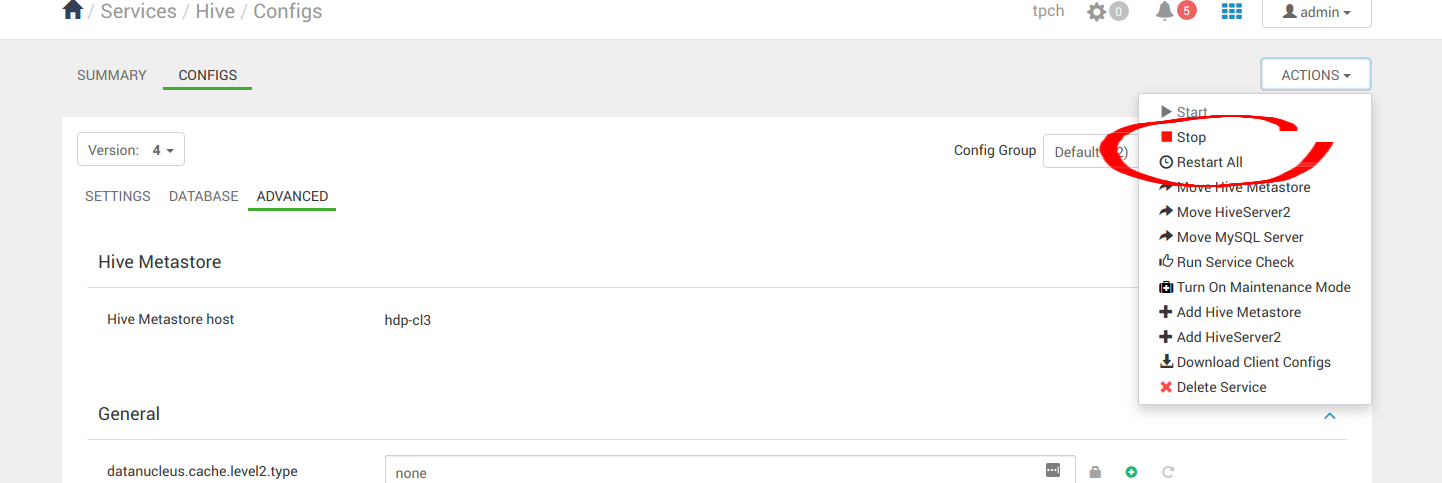
That’s it you can now test out your integration.
Explore on Your Own
This blog post has outlined a modern approach to migrating from Hadoop without the need to completely overhaul your existing systems. By leveraging Kubernetes to manage Apache Spark and Apache Hive, and integrating MinIO for stateful object storage, organizations can achieve a balanced architecture that supports dynamic scaling and efficient resource utilization. This setup not only retains but enhances the capabilities of your data processing environments, making them more robust and future-proof.
With MinIO, you benefit from a storage solution that offers high performance on commodity hardware, reduces costs through erasure coding (eliminating the redundancy of Hadoop's data replication), and bypasses limitations like vendor lock-in and the need for Cassandra-based metadata stores. These advantages are crucial for organizations looking to leverage advanced AI/ML workloads without discarding the core elements of their existing data systems.
Feel free to reach out for more detailed discussions or specific guidance on how you can tailor this migration strategy to meet the unique needs of your organization. Whether through email at hello@min.io or on our community