

Authors:
(1) Keivan Alizadeh;
(2) Iman Mirzadeh, Major Contribution;
(3) Dmitry Belenko, Major Contribution;
(4) S. Karen Khatamifard;
(5) Minsik Cho;
(6) Carlo C Del Mundo;
(7) Mohammad Rastegari;
(8) Mehrdad Farajtabar.
Table of Links
2. Flash Memory & LLM Inference and 2.1 Bandwidth and Energy Constraints
3.2 Improving Transfer Throughput with Increased Chunk Sizes
3.3 Optimized Data Management in DRAM
4.1 Results for OPT 6.7B Model
4.2 Results for Falcon 7B Model
6 Conclusion and Discussion, Acknowledgements and References
3.2 Improving Transfer Throughput with Increased Chunk Sizes
To increase data throughput from flash memory, it is crucial to read data in larger chunks, preferably sized as the multiples of the block size of the underlying storage pool. In this section, we detail the strategy we have employed to augment the chunk sizes for more efficient flash memory reads.

Bundling Based on Co-activation. We had a conjecture that neurons may be highly correlated
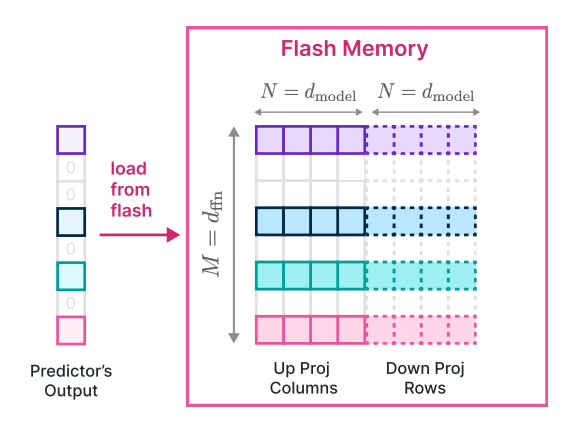
in their activity patterns, which may enable further bundling. To verify this we calculated the activations of neurons over C4 validation dataset. For each neuron the coactivation of that neuron with other ones forms a power law distribution as depicted in Figure 6a. Now, let’s call the neuron that coactivates with a neuron the most closest friend. Indeed, the closest friend of each neuron coactivates with it very often. As Figure 6b demonstrates, it is interesting to see each neuron and its closest friend coactivate with each other at least 95% of the times. The graphs for the 4th closest friend and 8th closest friend are also drawn. Based on this information we decided to put a bundle of each neuron and its closest friend in the flash memory; whenever a neuron is predicted to be active we’ll bring its closes friend too. Unfortunately, this resulted in loading highly active neurons multiple times and the bundling worked against our original
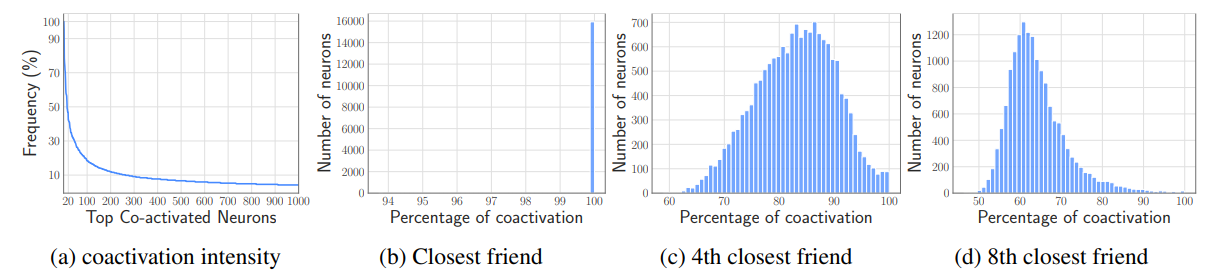
intention. It means, the neurons that are very active are ‘closest friend‘ of almost everyone. We intentionally present this negative result, as we believe it may lead to interesting future research studies on how to effectively bundle the neurons and how to leverage it for efficient inference.
This paper is available on arxiv under CC BY-SA 4.0 DEED license.