

Authors:
(1) Pinelopi Papalampidi, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh;
(2) Frank Keller, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh;
(3) Mirella Lapata, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh.
Table of Links
- Abstract and Intro
- Related Work
- Problem Formulation
- Experimental Setup
- Results and Analysis
- Conclusions and References
- A. Model Details
- B. Implementation Details
- C. Results: Ablation Studies
3. Problem Formulation
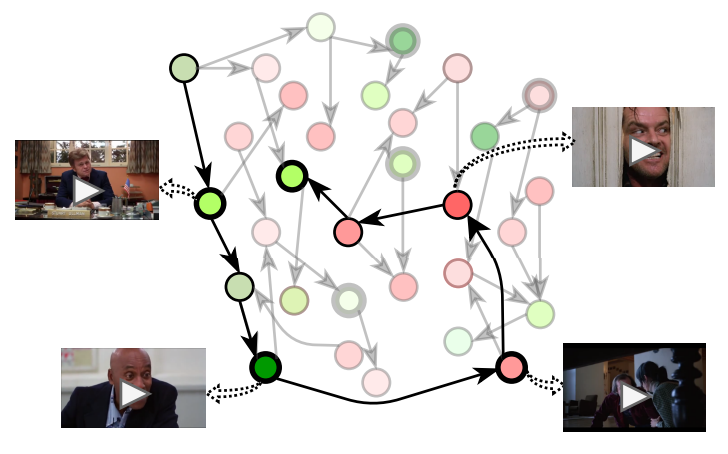
Trailer generation requires the selection of L shots from a full-length movie of M shots (L M). Movies present complex stories that may contain distinct subplots or events that unfold non-linearly, while redundant events, called “fillers” enrich the main story. Hence, we cannot assume that consecutive shots are necessarily semantically related. To better explore relations between events, we represent movies as graphs [42]. Let G = (V, E) denote a graph where vertices V are shots and edges E represent their semantic similarity. We further consider the original temporal order of shots in G by only allowing directed edges from previous to future shots. G is described by an upper triangular transition matrix T , which records the probability of transitioning from shot i to every future shot j.
Within G, we assume that some shots describe key events in the movie (thick circles in Figure 2) while all shots have a sentiment (positive or negative), whose intensity is denoted by a score (shades of green/red in Figure 2). We propose an algorithm for traversing G and selecting sequences of trailer shots. In the following, we first describe this algorithm (Section 3.1) and then discuss how the graph G is learned and key events are detected via TP identification [41] (Section 3.2). Finally, we also explain how shot-based sentiment scores are predicted (Section 3.5).
3.1. Movie Graph Traversal


We select L shots in total (depending on a target trailer length) and retrieve a proposal trailer sequence as depicted in Figure 2 (bold line). At each step, we keep track of the sentiment flow created and the TPs identified thus far (lines 10 and 13–14 in Algorithm 1, respectively). A TP event has been selected for presentation in the trailer if a shot or its immediate neighbors have been added to the path.
3.2. TP Identification




The video-based model assumes access to shot-level TP labels. However, the only dataset for TP identification we are aware of is TRIPOD [41], which contains scene-level labels based on screenplays. To obtain more fine-grained labels, we project scene-based annotations to shots following a simple one-to-many mapping (see Section 4 for details). Since our training signal is unavoidably noisy, we hypothesize that access to screenplays would encourage the videobased model to select shots which are more representative for each TP. In other words, screenplays represent privileged knowledge and an implicit supervision signal, while alleviating the need for additional pre-processing during inference. Moreover, screenplays provide a wealth of additional information, e.g., about characters and their roles in a scene, or their actions and emotions (conveyed by lines describing what the camera sees). This information might otherwise be difficult to accurately localize in video. Also, unlabeled text corpora of screenplays are relatively easy to obtain and can be used to pre-train our network.
3.3. Knowledge Distillation
We now describe our joint training regime for the two networks which encapsulate different views of the movie in terms of data streams (multimodal vs. text-only) and their segmentation into semantic units (shots vs. scenes).


Representation Consistency Loss We propose using a second regularization loss between the two networks in order to also enforce consistency between the two graphbased representations (i.e., over video shots and screenplay scenes). The purpose of this loss is twofold: to improve TP predictions for the two networks, as shown in previous work on contrastive representation learning [38, 39, 48], and also to help learn more accurate connections between shots (recall that the shot-based graph serves as input to our trailer generation algorithm; Section 3.1). In comparison with screenplay scenes, which describe self-contained events in a movie, video shots are only a few seconds long and rely on surrounding context for their meaning. We hypothesize that by enforcing the graph neighborhood for a shot to preserve semantics similar to the corresponding screenplay scene, we will encourage the selection of appropriate neighbors in the shot-based graph.


3.4. Self-supervised Pretraining
Pretraining aims to learn better scene representations from screenplays which are more accessible than movie videos (e.g., fewer copyright issues and less computational overhead) in the hope that this knowledge will transfer to the video-based network via our consistency losses.

3.5. Sentiment Prediction
Finally, our model takes into account how sentiment flows from one shot to the next. We predict sentiment scores per shot with the same joint architecture (Section 3.3) and training regime we use for TP identification. The video-based network is trained on shots with sentiment labels (i.e., positive, negative, neutral), while the screenplay-based network is trained on scenes with sentiment labels (Section 4 explains how the labels are obtained). After training, we predict a probability distribution over sentiment labels per shot to capture sentiment flow and discriminate between high- and low-intensity shots (see Appendix for details).
This paper is available on arxiv under CC BY-SA 4.0 DEED license.