

Authors:
(1) Sasun Hambardzumyan, Activeloop, Mountain View, CA, USA;
(2) Abhinav Tuli, Activeloop, Mountain View, CA, USA;
(3) Levon Ghukasyan, Activeloop, Mountain View, CA, USA;
(4) Fariz Rahman, Activeloop, Mountain View, CA, USA;.
(5) Hrant Topchyan, Activeloop, Mountain View, CA, USA;
(6) David Isayan, Activeloop, Mountain View, CA, USA;
(7) Mark McQuade, Activeloop, Mountain View, CA, USA;
(8) Mikayel Harutyunyan, Activeloop, Mountain View, CA, USA;
(9) Tatevik Hakobyan, Activeloop, Mountain View, CA, USA;
(10) Ivo Stranic, Activeloop, Mountain View, CA, USA;
(11) Davit Buniatyan, Activeloop, Mountain View, CA, USA.
Table of Links
- Abstract and Intro
- Current Challenges
- Tensor Storage Format
- Deep Lake System Overview
- Machine Learning Use Cases
- Performance Benchmarks
- Discussion and Limitations
- Related Work
- Conclusions, Acknowledgement, and References
ABSTRACT
Traditional data lakes provide critical data infrastructure for analytical workloads by enabling time travel, running SQL queries, ingesting data with ACID transactions, and visualizing petabytescale datasets on cloud storage. They allow organizations to break down data silos, unlock data-driven decision-making, improve operational efficiency, and reduce costs. However, as deep learning usage increases, traditional data lakes are not well-designed for applications such as natural language processing (NLP), audio processing, computer vision, and applications involving non-tabular datasets. This paper presents Deep Lake, an open-source lakehouse for deep learning applications developed at Activeloop[1][2]. Deep Lake maintains the benefits of a vanilla data lake with one key difference: it stores complex data, such as images, videos, annotations, as well as tabular data, in the form of tensors and rapidly streams the data over the network to (a) Tensor Query Language, (b) in-browser visualization engine, or (c) deep learning frameworks without sacrificing GPU utilization. Datasets stored in Deep Lake can be accessed from PyTorch [58], TensorFlow [25], JAX [31], and integrate with numerous MLOps tools.
KEYWORDS - Deep Lake, Deep Learning, Data Lake, Lakehouse, Cloud Computing, Distributed Systems
1. INTRODUCTION
A data lake is a central repository that allows organizations to store structured, unstructured, and semi-structured data in one place. Data lakes provide a better way to manage, govern, and analyze data. In addition, they provide a way to break data silos and gain insights previously hidden in disparate data sources. First-generation data lakes traditionally collected data into distributed storage systems such as HDFS [71] or AWS S3 [1]. Unorganized collections of the data turned data lakes into "data swamps", which gave rise to the second-generation data lakes led by Delta, Iceberg, and Hudi [27, 15, 10]. They strictly operate on top of standardized structured formats such as Parquet, ORC, Avro [79, 6, 20] and provide features like time travel, ACID transactions, and schema evolution. Data lakes directly integrate with query engines such as Presto, Athena,
Hive, and Photon [70, 12, 76, 66] to run analytical queries. Additionally, they connect to frameworks like Hadoop, Spark, and Airflow [14, 82, 9] for ETL pipeline maintenance. In its turn, the integration between data lakes and query engines with clear compute and storage separation resulted in the emergence of systems like Lakehouse [28] that serve as an alternative to data warehouses, including Snowflake, BigQuery, Redshift, and Clickhouse [33, 4, 40, 2].
Over the past decade, deep learning has outpaced traditional machine learning techniques involving unstructured and complex data such as text, images, videos, and audio [44, 47, 38, 83, 51, 30, 63, 56]. Not only did deep learning systems outgrow traditional techniques, but they also achieved super-human accuracy in applications such as cancer detection from X-ray images, anatomical reconstruction of human neural cells, playing games, driving cars, unfolding proteins, and generating images [61, 48, 72, 42, 77]. Large language models with transformer-based architectures achieved state-of-the-art results across translation, reasoning, summarization, and text completion tasks [78, 36, 81, 32]. Large multi-modal networks embed unstructured data into vectors for cross-modal search [29, 60]. Moreover, they are used to generate photo-realistic images from text [62, 65].
Although one of the primary contributors to the success of deep learning models has been the availability of large datasets such as CoCo (330K images), ImageNet (1.2M images), Oscar (multilingual text corpus), and LAION (400M and 5B images) [49, 34, 74, 68], it does not have a well-established data infrastructure blueprint similar to traditional analytical workloads to support such scale. On the other hand, Modern Data Stack (MDS) lacks the features required to deploy performant deep learning-based solutions so organizations opt to develop in-house systems.
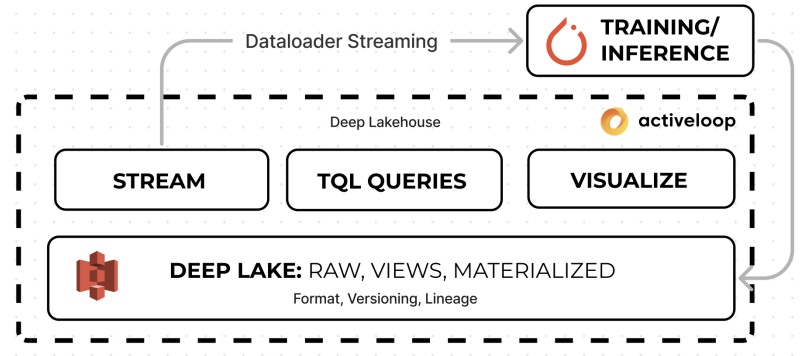
In this paper, we introduce Deep Lake, a lakehouse specialized for deep learning workloads. Deep Lake retains the main benefits of a
traditional data lake with one notable distinction: it stores complex data, such as images, videos, annotations, and tabular data, as tensors and rapidly streams the data to deep learning frameworks over the network without sacrificing GPU utilization. Furthermore, it provides native interoperability between deep learning frameworks such as PyTorch, TensorFlow, and JAX [58, 25, 31].
The main technical contributions of this paper include:
• Tensor Storage Format that stores dynamically shaped arrays on object storage;
• Streaming Dataloader that schedules fetching, decompression, and user-defined transformations, optimizing data transfer throughput to GPUs for deep learning;
• Tensor Query Language running SQL-like operations on top of multi-dimensional array data;
• In-browser visualization engine that streams data from object storage and renders it in the browser using WebGL.
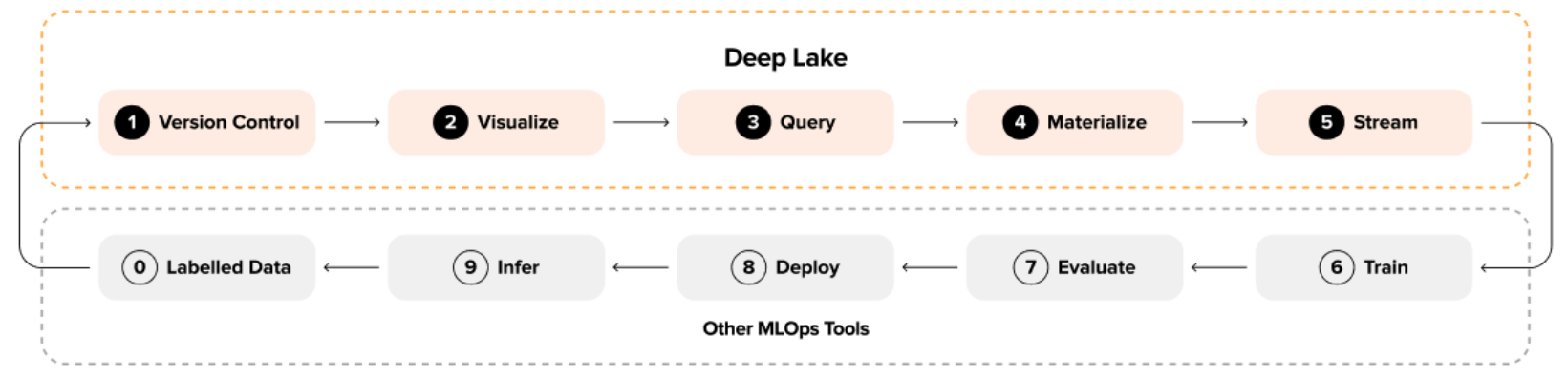
The remainder of this paper unfolds as follows. We begin by considering current challenges in deep learning on unstructured data. Next, we present the Tensor Storage Format (TSF) with its key concepts. Furthermore, we discuss Deep Lake’s capabilities and applications within the ML cycle. Next, we provide performance experiments and discuss the results. Finally, we review related work, list possible limitations, and conclude.
This paper is available on arxiv under CC 4.0 license.
[1] Source code available: https://github.com/activeloopai/deeplake
[2] Documentation available at https://docs.deeplake.ai