

Authors:
(1) Iason Ofeidis, Department of Electrical Engineering, and Yale Institute for Network Science, Yale University, New Haven {Equal contribution};
(2) Diego Kiedanski, Department of Electrical Engineering, and Yale Institute for Network Science, Yale University, New Haven {Equal contribution};
(3) Leandros TassiulasLevon Ghukasyan, Activeloop, Mountain View, CA, USA, Department of Electrical Engineering, and Yale Institute for Network Science, Yale University, New Haven.
Table of Links
- Abstract and Intro
- Dataloaders
- Experimental Setup
- Numerical Results
- Discussion
- Related Work
- Conclusion, Acknowledgments, and References
- A. Numerical Results Cont.
4. NUMERICAL RESULTS
For the first set of experiments, we evaluated the performance of all libraries when changing the number of workers (see 2) as well as the batch size. These experiments were run in a local server with the following specifications: Intel(R) Core(TM) i9-10900K, 2 x NVIDIA GeForce RTX 3090, and an HDD with 10TB of storage (6GB/s) [5].
We evaluated the three modes: default (single GPU), distributed (two GPUs), and filtering (single GPU) for all possible combinations of 0, 1, and 2 workers. For CIFAR10 and RANDOM, the batch size was either 16, 64, or 128. For CoCo, we used smaller values: 1, 2, and 4. All these experiments used a cutoff of 10 and the variant that runs the model (forward & backward pass).
4.1 Speed as a function of batch size and workers
The first thing we notice while examining the experiments is that the variance between libraries depends on the problem and the dataset used. Figure 4 shows one such comparison for CIFAR10 on a single GPU, whereas 5 show the same result for CoCo, also on a single GPU.
This was to be expected given that in the latter, the time taken to compute the forward and backward pass dominates the overall running time, which is not the case for image
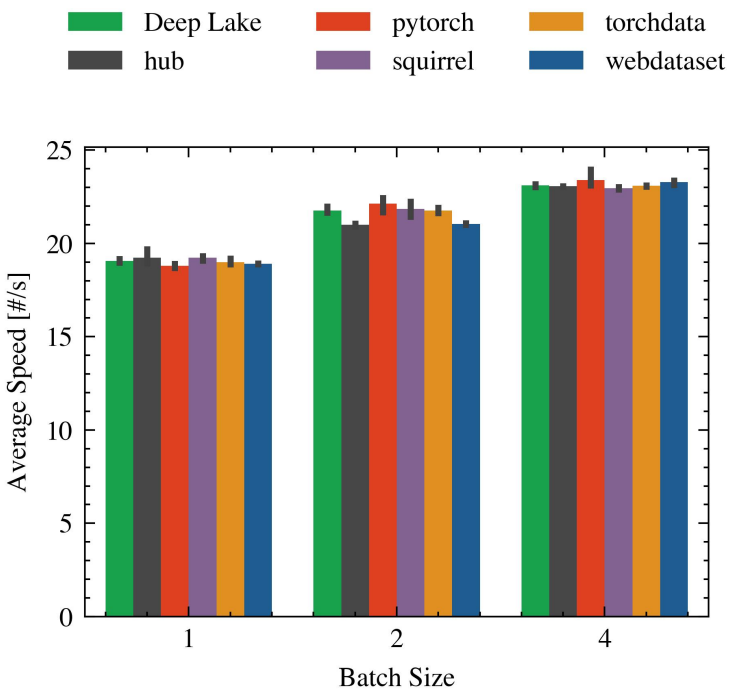
classification. You may also note the overall difference in speed: from 4000 samples per second to only 20.
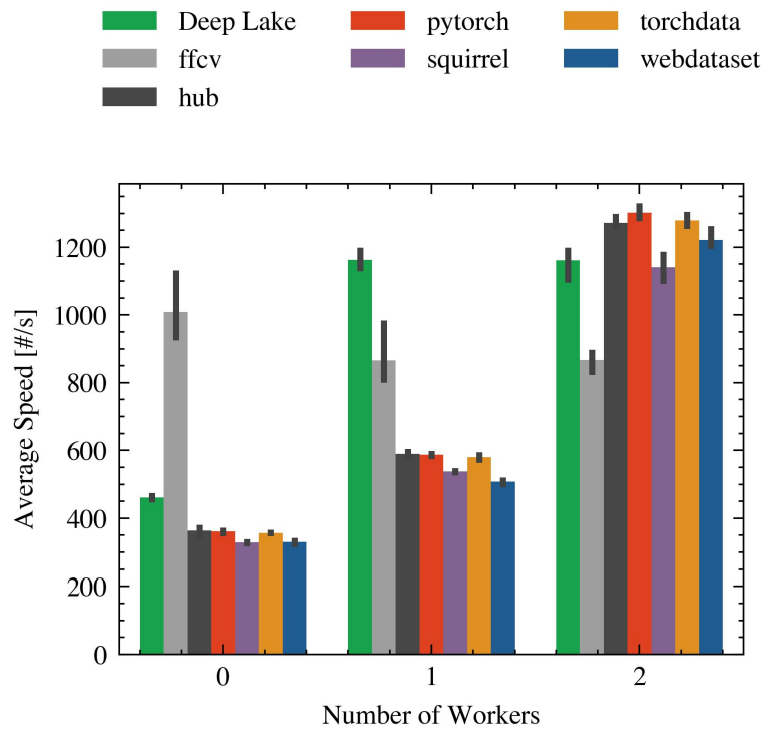
Secondly, we point out that increasing the batch size increases processing speed in almost all cases. However, this is not the case for the number of workers. We can observe in Figure 6 that FFCV performance degrades as the number of workers increases, while Deep Lake plateaus at 1 worker and not 2. One explanation is that the libraries have their own internal algorithms that decide how to span threads and processes as needed. The point above is relevant for users of these libraries, as experience with one of them might not translate well into another one.
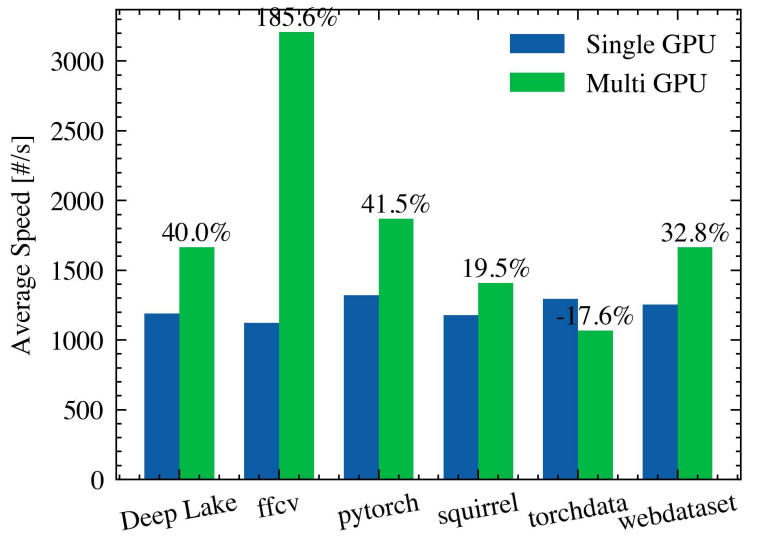
4.2 Speed Gains when using DDP
A desirable feature of a dataloader is its ability to scale linearly with the number of GPUs. This is not always possible and depends on the internal loading mechanism of each library. We explore how these libraries performed by comparing the speed increase when using one or two GPUs. Figure 7 shows the results for the RANDOM dataset. Each bar represents the maximum speed achieved across all batch sizes, number of workers, and repetitions. In a way, this reflects the maximum speed achievable by the library. We observe that libraries speed up about 40%, less than half of a linear increase on average. Two cases are particularly surprising. On the one hand, Torchdata performs worse with two GPUs than on a single one. On the other hand, FFCV achieved a speed increase of more than theoretically possible. There are several artifacts that can be at play here, but most likely, it is due to the limited number of repetitions we were able to run (due to limited resources). Also, this might
indicate a misconfiguration in Torchdata: the documentation on running experiments in multi-GPU environments is limited for most libraries.
4.3 Comparison between with and without forward and backward pass
As we discussed when presenting Algorithm 1, we had to decide whether we would incorporate the forward and backward passes into the speed calculation. There are arguments for both. On the one hand, including the forward and backward passes better reflect the algorithm’s actual training time. At the same time, some libraries might preemptively optimize steps normally done during the forward pass, so
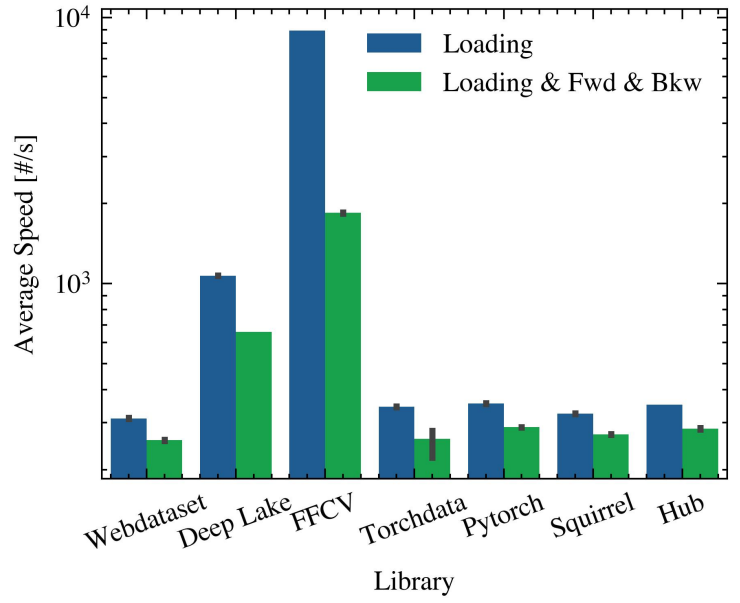
stopping there would seem as if they take longer than they do.
On the other hand, if the time taken by the forward and backward pass is much larger than the time it takes for only loading the data, including that time in the calculation would inevitably hide the difference between libraries.
To understand if the behavior change was noticeable, we used the RANDOM dataset to compare the difference in average speed when including the two model operations in the calculation and when not. The results are presented in Figure 8. We can observe that most libraries have a slightly increased speed when excluding the model (except for FFCV, whose performance drops in half), and most importantly, the relative performance among libraries remains almost the same.
4.4 Speed trade-offs when filtering data
For our filtering experiments, we selected two classes to keep for CIFAR10 and RANDOM: dog and truck, and 0 and 13, respectively. For CoCO we selected three classes: pizza, couch, cat.
We observed that most libraries do not have a good filtering mechanism that avoids iterating over the whole dataset. For example, our PyTorch filtering implementation requires building a custom sampler with the indices of the desired images.
This is quite fast for a small dataset but becomes unfeasible for large datasets: filtering CoCo using PyTorch was prohibitively expensive. In general, performance was quite similar when filtering and when not[6]. Similarly to Figure
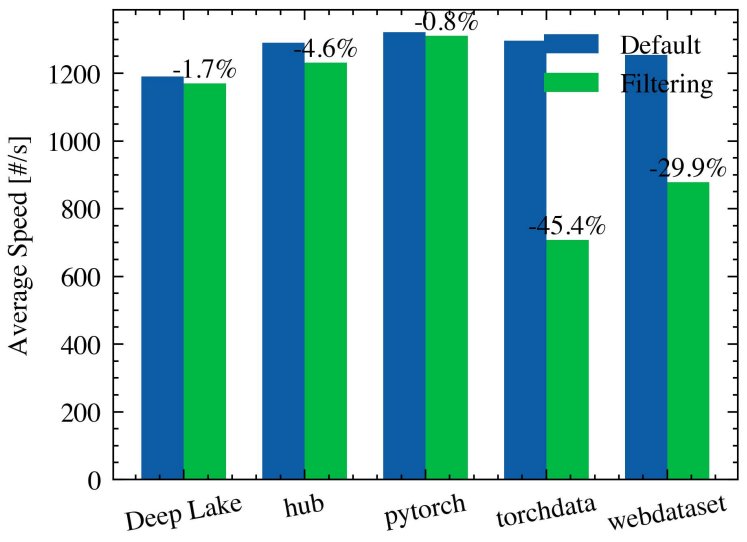
7, in Figure 9, we can see the slowdown as a result of filtering: even though it was considerable for Torchdata and Webdataset, we saw a reversal of the results when working with the CoCo Dataset.
4.5 Training while streaming over the network
Ideally, we could decouple the dataset storage from the machine learning training process and simply connect the database storing our data to the ML framework of choice, regardless of where the two are located. That involves sending the training data over a network and losing considerable speed. With the high costs involved in renting GPU accelerated hardware on the cloud, it might seem that the convenience is not worth it. But is it not?
Some of the libraries considered in this paper allow specifying a dataset accessible via the internet: Webdataset, Hub, and Deep Lake are particularly good at this[7]. The question then becomes: how big is the tradeoff between ease of usage and running time?
We set up the following experiment to offer some insight into this question. We ran two full epochs of the RANDOM dataset for the three libraries: Hub, Deep Lake, and Webdataset, while changing the origin of the data. Three locations were considered: a local copy in the machine running the experiments’ hard drive, a copy in an S3 bucket (in the closest region to our machine), and a copy stored in MinIO (an open source equivalent of S3 that can be hosted locally) running in a similar machine within the same local network (both machines were connected via WiFi). The experiments’ computer had an Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz, 16 GB of RAM, NVIDIA GeForce RTX
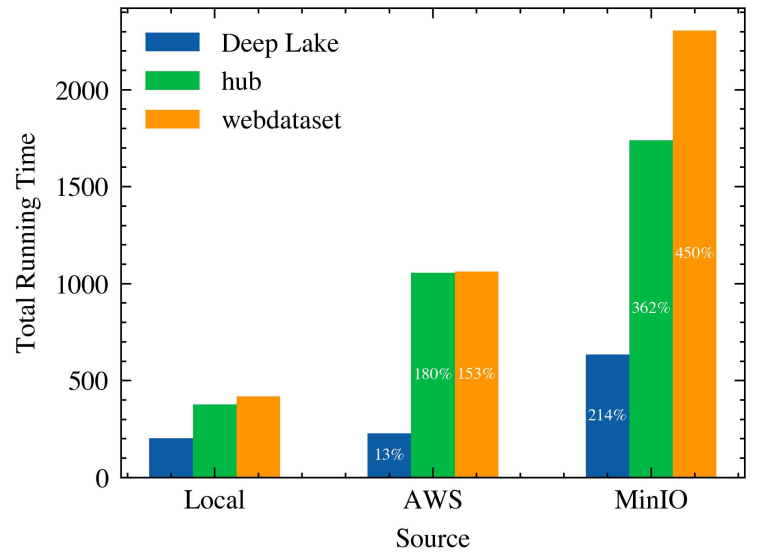
2070 Rev, and a Samsung SSD 850 hard drive with 256 GB of storage. Regarding latency, the Round Trip Time from the workstation running the experiments to the MinIO server (located in the same room and in the same local WiFi) took 59.2 ± 58.5ms (min. 8.8ms), while to the S3-bucket in AWS servers took 17.3 ± 1.3ms (min. 14.8ms).
Figure 10 depicts the total running times for the nine experiments, and the white percentages denote the slowdown (increase in running time) compared to the local case. We can observe that even though for Hub and Webdataset there is a significant increase when moving to AWS, Deep Lake managed to maintain almost the same speed with an increase of only 13%. Another helpful insight could be extracted from the result: the MinIO setting shows a slowdown almost twice as bad as the AWS setting, as seen in Figure 10. This output could be explained primarily by the difference in average Round Trip Times shown above, highlighting that local networks (e.g., internal company networks[8]) might not be the most efficient way to host datasets due to their complex configurations and restrictions. Furthermore, this result also indicates that the storage serving the datasets over the network plays a crucial role in enabling remote training and might trigger questions on best practices to serve datasets. Namely, data from S3 is served in parallel from different servers with load balancing while we had access to a single MinIO instance.
The plots for all additional experiments can be found in Appendix A.
This paper is available on arxiv under CC 4.0 license.
[5] https://www.seagate.com/www-content/productcontent/barracuda-fam/barracuda-new/enus/docs/100835983b.pdf
[6] in speed. Building the sampler for PyTorch is done upfront, considerably affecting the total running time.
[7] Squirrel has this capability, but we did not manage to specify a MinIO address, so we excluded it from the comparison. We had a similar issue with Torchdata.
[8] In this case a university network